🚀 𝗔𝗿𝗾𝘂𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗮𝘀 𝗱𝗲 𝗗𝗮𝘁𝗼𝘀 (𝗔𝘇𝘂𝗿𝗲, 𝗔W𝗦, 𝗚𝗼𝗼𝗴𝗹𝗲 𝘆 𝗢𝗽𝗲𝗻 𝗦𝗼𝘂𝗿𝗰𝗲), comparativa muy útil!!
* Para la Arquitectura Open Source he tomado como referencia: https://lnkd.in/dDf_kyj4
* Aquí puedes descargar la imagen en fichero de alta calidad: https://lnkd.in/dv2hiugp
CONTENIDO:
𝟭. 𝗜𝗻𝗳𝗿𝗮𝗲𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗮
- Regiones disponibles globalmente
- Escalabilidad automática de recursos
- Compatibilidad híbrida
- Tiempo de despliegue
𝟮. 𝗔𝗹𝗺𝗮𝗰𝗲𝗻𝗮
Leer más...
🚀 Los mejores libros de gestión, tecnología e innovación
🕓 He resumido los 40 Consejos más importantes que he seguidoAl principio, de libros físicos, como la fotografía de algunos libros de mi biblioteca y, más recientemente, de forma digital.
Los he agrupado en:
✔️ Empresa
✔️ Negocios
✔️ Datos
✔️ Innovación
DESCARGAR:
40frases_Management40frases_Management.pdf4
Leer más...
🚀 El problema del sesgo en IA y ML empieza con la definición misma del término “sesgo”. Os traigo un 𝗧𝘂𝘁𝗼𝗿𝗶𝗮𝗹 𝘀𝗼𝗯𝗿𝗲 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗲 𝗜𝗔: 𝗤𝘂𝗲 𝗲𝘀 𝗲𝗹 𝘀𝗲𝘀𝗴𝗼? 𝗧𝗲𝗰𝗻𝗼𝗹𝗼𝗴í𝗮𝘀 𝘆 𝗮𝗹𝗴𝗼𝗿𝗶𝘁𝗺𝗼𝘀 𝗽𝗮𝗿𝗮 𝗰𝗼𝗺𝗯𝗮𝘁𝗶𝗿𝗹𝗼
🔎 Este término está sobrecargado y tiene un significado drásticamente distinto bajo diferentes contextos.En estadística, el sesgo es la diferencia entre el valor esperado de un estimador (predicción) y su
Leer más...
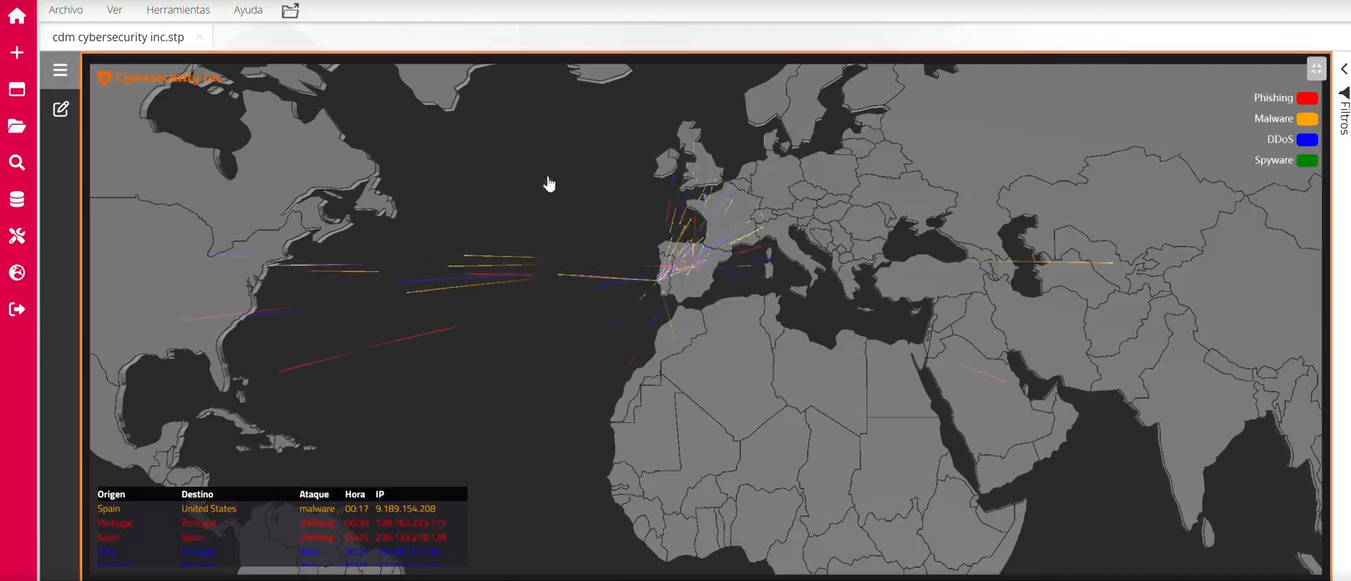
🚀 Dashboard con 𝟭𝟱 𝗞𝗣𝗜𝘀 𝗰𝗹𝗮𝘃𝗲 𝗱𝗲 #𝗖𝗶𝗯𝗲𝗿𝘀𝗲𝗴𝘂𝗿𝗶𝗱𝗮𝗱 𝗗𝗶𝗴𝗶𝘁𝗮𝗹 que debes analizar para evitar ataques y hackeos!!
𝟭. 𝗧𝗶𝗲𝗺𝗽𝗼 𝗠𝗲𝗱𝗶𝗼 𝗽𝗮𝗿𝗮 𝗗𝗲𝘁𝗲𝗰𝘁𝗮𝗿 (𝗠𝗧𝗧𝗗)Phishing, Malware, DDoS...Tiempo promedio para identificar cualquier tipo de ataque después de su inicio
𝟮. 𝗧𝗶𝗲𝗺𝗽𝗼 𝗠𝗲𝗱𝗶𝗼 𝗽𝗮𝗿𝗮 𝗥𝗲𝘀𝗽𝗼𝗻𝗱𝗲𝗿 (𝗠𝗧𝗧𝗥, 𝗠𝗲𝗮𝗻 𝗧𝗶𝗺𝗲 𝘁𝗼 𝗥𝗲𝘀𝗽𝗼𝗻𝗱)Tiempo promedio que tarda el equipo en contener y resolver incidentes. Importante
Leer más...
🚀 Esta es la mejor 𝗚𝘂í𝗮 𝗽𝗮𝗿𝗮 𝗴𝗲𝘀𝘁𝗶𝗼𝗻𝗮𝗿 𝗹𝗼𝘀 𝗰𝗼𝘀𝘁𝗲𝘀 𝗲𝗻 𝗦𝗻𝗼𝘄𝗳𝗹𝗮𝗸𝗲. El DW en Cloud que ha revolucionado el mundo de los Data Lakes!!
🔎 Paso a paso:
1. Activa auto-suspend y auto-resume (activado por default)
2. Configura 'Resource monitors'
3. Establece un presupuesto a nivel de cuenta
4. Empieza con un pequeño warehouse
5.
Leer más...
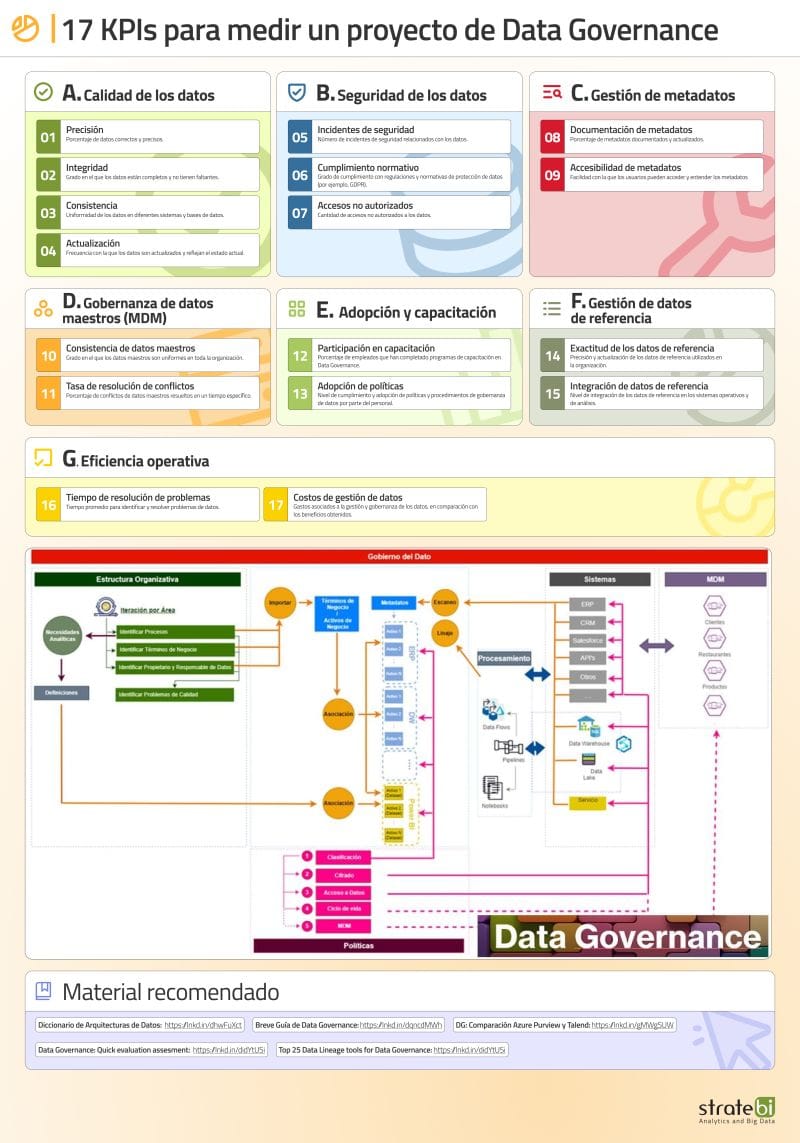
🚀 Estos son 17 indicadores clave (KPIs) que te pueden ayudar a medir la efectividad de un proyecto de Data Governance
Suelo construir un dashboard en #powerbi para controlar todos ellos
𝗔. 𝗖𝗮𝗹𝗶𝗱𝗮𝗱 𝗱𝗲 𝗹𝗼𝘀 𝗱𝗮𝘁𝗼𝘀:
1) Precisión: Porcentaje de datos correctos y precisos.
2) Integridad: Grado en el que los datos están completos y no
Leer más...
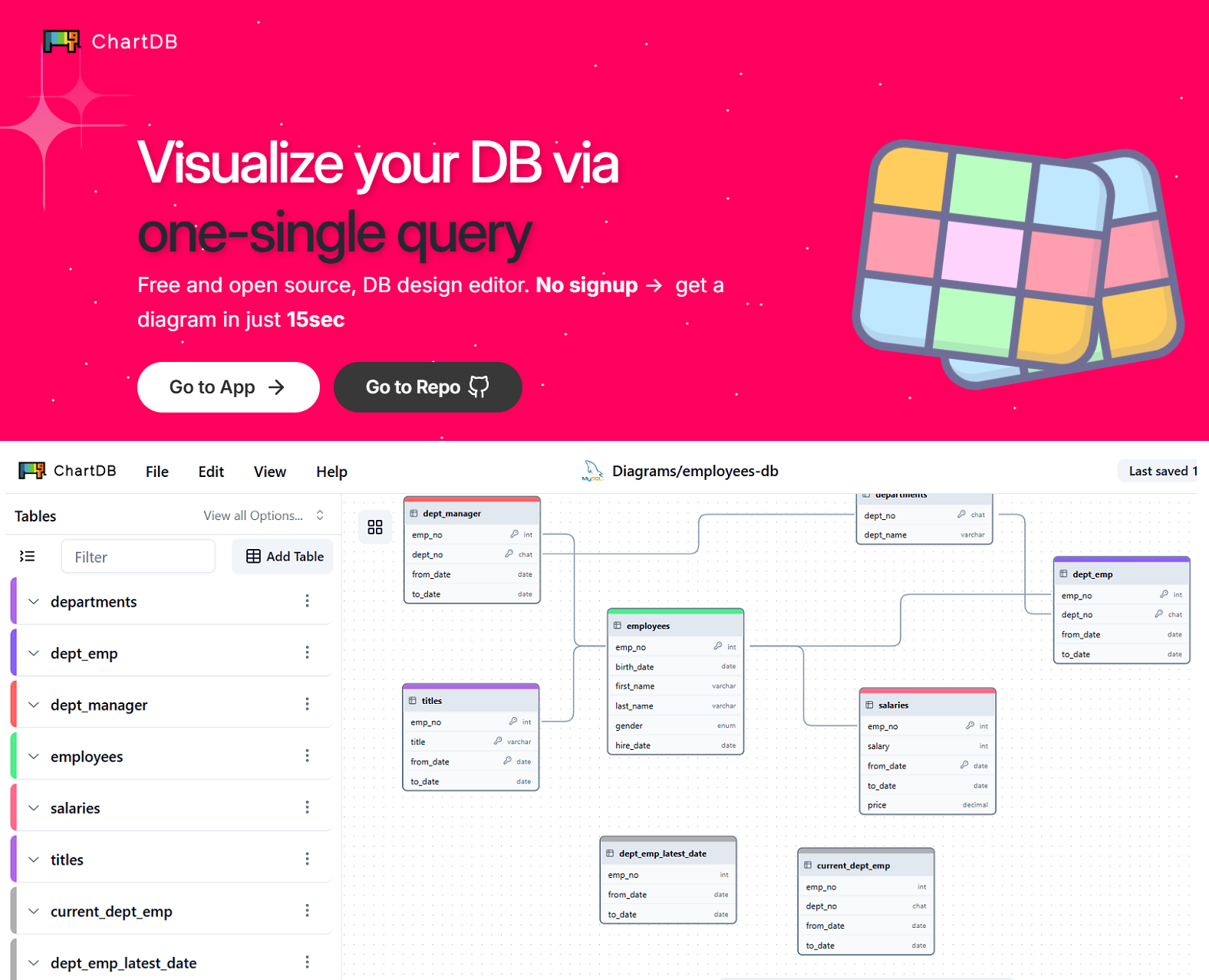
🚀 𝗖𝗵𝗮𝗿𝘁𝗗𝗕 es una nueva herramienta de código abierto diseñada para la visualización y edición de esquemas de bases de datos de forma rápida y accesible
W𝗲𝗯: https://chartdb.io/
𝗗𝗲𝘀𝗰𝗮𝗿𝗴𝗮: https://lnkd.in/dv44x9Nz
𝗢𝘁𝗿𝗮𝘀 𝗮𝗹𝘁𝗲𝗿𝗻𝗮𝘁𝗶𝘃𝗮𝘀 𝘀𝗶𝗺𝗶𝗹𝗮𝗿𝗲𝘀 𝘀𝗲𝗿í𝗮𝗻: https://dbeaver.io/, https://www.pgadmin.org/, https://www.heidisql.com/, https://drawsql.app/, https://lnkd.in/
Leer más...
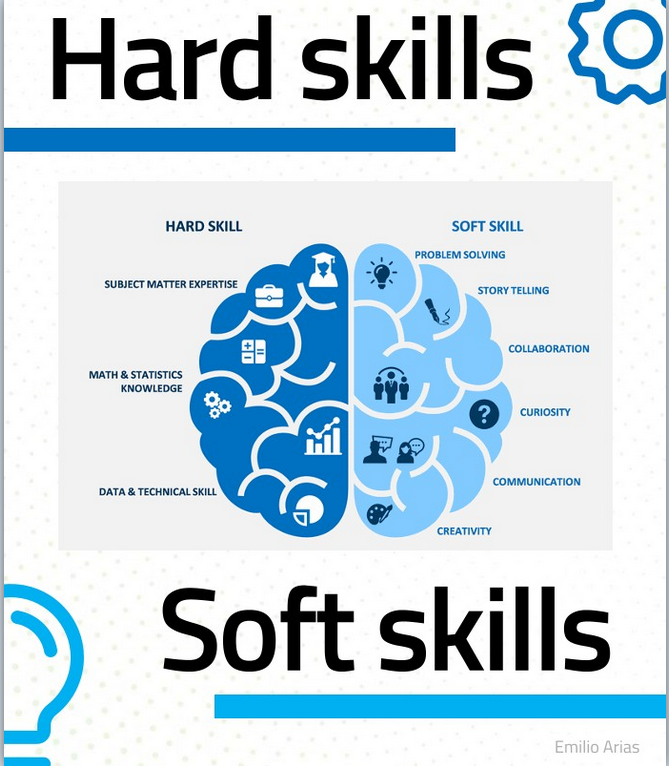
🚀 Os comparto la charla que suelo dar en empresas de IT y que he visto que funciona
🔎 Ya os digo, que las personas son más importantes que la tecnología
Espero que os sea de utilidad.!!
Descargar gratuitamente:
final_soft-skillsfinal_soft-skills.pdf2 MBdownload-circle
Leer más...
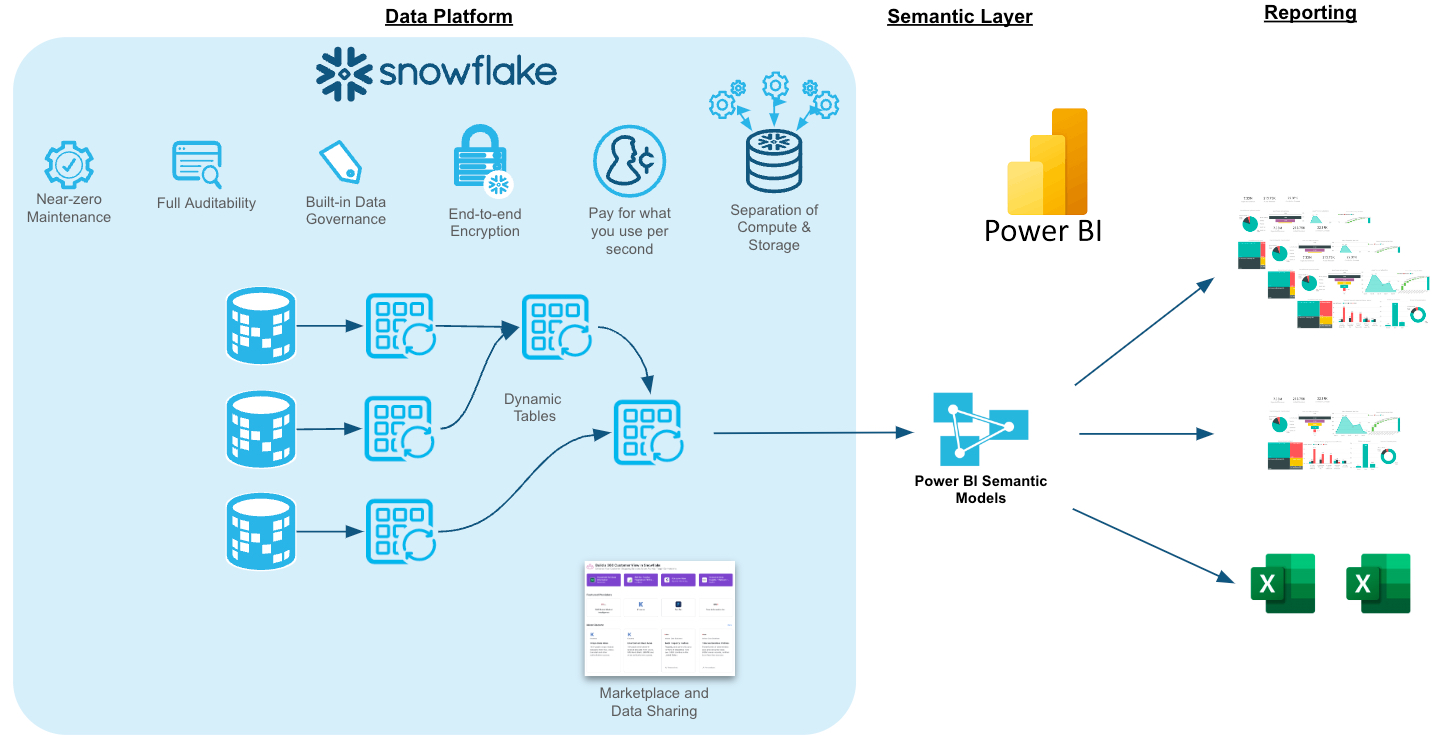
🚀 Si trabajas o quieres hacerlo con #Snowflake y #PowerBI de forma conjunta, éste es el Tutorial gratuito más práctico
𝗖𝗢𝗡𝗧𝗘𝗡𝗜𝗗𝗢:
Acceso: https://lnkd.in/dFnZEpmj
1. Overview
2. Reviewing the Dataset
3. Third Party Data from Snowflake Marketplace
4. Transforming Data with Dynamic Tables
5. Protecting Sensitive Data with Snowflake Horizon
Leer más...