

Machine learning
Machine learning is the process through which a computer learns with experience rather than additional programming.
Let’s say you use a program to determine which customers receive which discount offers. If it’s a machine-learning program, it will make better recommendations as it gets more data about how customers respond. The system gets better at its task by seeing more data.
Algorithm
An algorithm is a set of specific mathematical or operational steps used to solve a problem or accomplish a task.
In the context of machine learning, an algorithm transforms or analyzes data. That could mean:
• performing regression analysis—“based on previous experiments, every $10 we spend on advertising should yield $14 in revenue”
• classifying customers—“this site visitor’s clickstream suggests that he’s a stay-at-home dad”
• finding relationships between SKUs—“people who bought these two books are very likely to buy this third title”
Each of these analytical tasks would require a different algorithm.
When you put a big data set through an algorithm, the output is typically a model.
Model
The simplest definition of a model is a mathematical representation of relationships in a data set.
A slightly expanded definition : “a simplified, mathematically formalized way to approximate reality (i.e. what generates your data) and optionally to make predictions from this approximation.”
Here’s a visualization of a really simple model, based on only two variables.
The blue dots are the inputs (i.e. the data), and the red line represents the model.
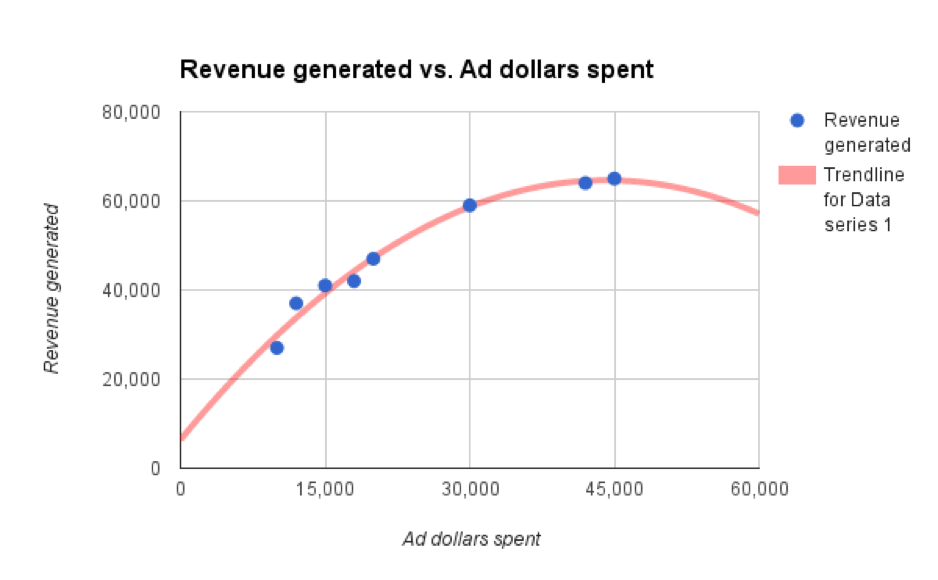
I can use this model to make predictions. If I put any “ad dollars spent” amount into the model, it will yield a predicted “revenue generated” amount.
Two key things to understand about models:
1. Models get complicated. The model illustrated here is simple because the data is simple. If your data is more complex, the predictive model will be more complex; it likely wouldn’t be portrayed on a two-axis graph.
When you speak to your smartphone, for example, it turns your speech into data and runs that data through a model in order to recognize it. That’s right, Siri uses a speech recognition model to determine meaning.
Complex models underscore why machine-learning algorithms are necessary: You can use them to identify relationships you would never be able to catch by “eyeballing” the data.
2. Models aren’t magic. They can be inaccurate or plain old wrong for many reasons. Maybe I chose the wrong algorithm to generate the model above. See the line bending down, as you pass our last actual data point (blue dot)? It indicates that this model predicts that past that point, additional ad spending will generate less overall revenue. This might be true, but it certainly seems counterintuitive. That should draw some attention from the marketing and data science teams.
A different algorithm might yield a model that predicts diminishing incremental returns, which is quite different from lower revenue.
Features
Wikipedia’s definition of a feature is good: “an individual measurable property of a phenomenon being observed. Choosing informative, discriminating, and independent features is a crucial step for effective algorithms.”
So features are elements or dimensions of your data set.
Let’s say you are analyzing data about customer behavior. Which features have predictive value for the others? Features in this type of data set might include demographics such as age, location, job status, or title, and behaviors such as previous purchases, email newsletter subscriptions, or various dimensions of website engagement.
You can probably make intelligent guesses about the features that matter to help a data scientist narrow her work. On the other hand, she might analyze the data and find “informative, discriminating, and independent features” that surprise you.
Supervised vs. unsupervised learning
Machine learning can take two fundamental approaches.
Supervised learning is a way of teaching an algorithm how to do its job when you already have a set of data for which you know “the answer.”
Classic example: To create a model that can recognize cat pictures via a supervised learning process, you would show the system millions of pictures already labeled “cat” or “not cat.”
Marketing example: You could use a supervised learning algorithm to classify customers according to six personas, training the system with existing customer data that is already labeled by persona.
Unsupervised learning is how an algorithm or system analyzes data that isn’t labeled with an answer, then identifies patterns or correlations.
An unsupervised-learning algorithm might analyze a big customer data set and produce results indicating that you have 7 major groups or 12 small groups. Then you and your data scientist might need to analyze those results to figure out what defines each group and what it means for your business.
In practice, most model building uses a combination of supervised and unsupervised learning, says Doyle.
“Frequently, I start by sketching my expected model structure before reviewing the unsupervised machine-learning result,” he says. “Comparing the gaps between these models often leads to valuable insights.”
Deep learning
Deep learning is a type of machine learning. Deep-learning systems use multiple layers of calculation, and the later layers abstract higher-level features. In the cat-recognition example, the first layer might simply look for a set of lines that could outline a figure. Subsequent layers might look for elements that look like fur, or eyes, or a full face.
Compared to a classical computer program, this is somewhat more like the way the human brain works, and you will often see deep learning associated with neural networks , which refers to a combination of hardware and software that can perform brain-style calculation.
It’s most logical to use deep learning on very large, complex problems. Recommendation engines (think Netflix or Amazon) commonly use deep learning.
Visto en Huffingtonpost