

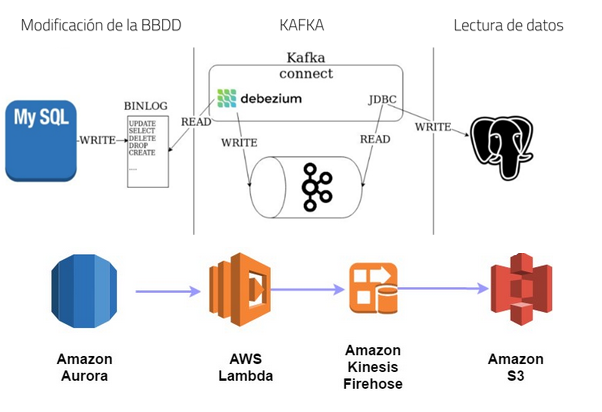
En bases de datos, las CDC (Change Data Capture) son patrones de diseño software que se emplean para capturar cambios que se producen en los datos y propagarlos a clientes intermedios.
Normalmente se emplean en entornos de data warehouse, para preservar el estado de los datos a lo largo del tiempo, o se emplean también en soluciones en las que hay que mantener un conjunto de bases de datos heterogéneo, ya que las CDC producen el mismo formato de salida independientemente de cuál sea la base de datos origen del registro.
CDC utilizando herramientas AWS
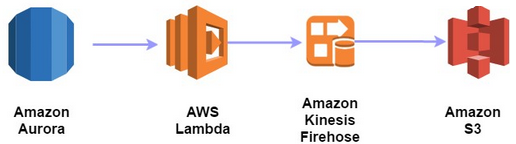
AWS permite la creación de un sistema de captura de cambio de datos (CDC) en Aurora mediante la utilización de los servicios “AWS Lambda”, “Amazon Kinesis Firehose” y “Amazon S3”.
· Aws Lambda: Es el servicio que proporciona AWS para la ejecución de código sin requerir administración ni aprovisionamiento de servidores.
· Amazon Kinesis Firehose: Es el servicio proporcionado por AWS para la carga de datos de streaming en lagos de datos, Data Warehouses y servicios analíticos.
· Amazon Simple Storage Service (Amazon S3): Es el servicio de Aws encargado del almacenamiento de estructuras de datos. Este servicio puede ser utilizado para varios fines como pueden ser lago de datos, almacén de copias de seguridad y restauraciones o almacenamiento de datos proveniente de dispositivos IoT.
La estructura del sistema CDC tendría la siguiente estructura:
La visualización de los datos almacenados en Amazon S3 podría realizarse con un conjunto de herramientas propias de Amazon como el formado por los servicios “Amazon Athenea” (servicio de consultas a los datos de Amazon S3 utilizando el lenguaje SQL estándar) y “Amazon QuickSight” (servicio de visualización de datos) o mediante la utilización de herramientas externas.
El orden de creación debe ir de extremo a extremo empezando por la creación de Amazon Kinesis y terminando por la creación de los procesos internos de la base de datos que desencadenen el resto de acciones.
Creación de Amazon Kinesis
El primer paso consiste en la creación del canal Kinesis Firehose, que se encargará de suministrar al repositorio Amazon S3 los datos que le vaya aportando la función lambda.
Para ello, desde la pestaña de secuencias de entrega, se debe crear una nueva secuencia en la que el destino sea Amazon S3

Posteriormente, se debe seleccionar el bucket de S3 en el que se almacenarán los datos.

Para terminar, se pueden establecer diferentes como el formato de compresión de los datos (GZIP, Snappy o ZIP) o la encriptación de los datos en S3.
También hay que tener en cuenta que en el apartado de roles IAM se debe seleccionar aquel rol que tenga permiso para escribir en S3 o generar uno nuevo.
Creación de la función lambda
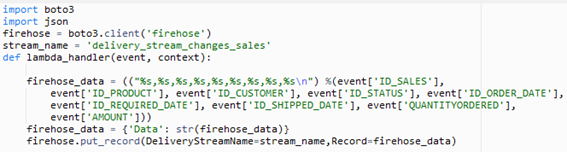
Con esta función lambda se recogerán los datos enviados por el procedimiento almacenado o por el trigger y concatena en un string todos los campos del Json creado en el paso anterior.
En este momento es en el que se debe dar la estructura en la que se desea representar la información . Esto se hará modificando la estructura del string que se almacena en la variable “firehose_data”.
Por último, la función lambda incluirá los datos en el canal de Kinesis Firehose mediante el uso de la función “firehose.put_record”. Esta función tiene como parámetros el nombre del canal de Kinesis y los datos a enviar.
Hay que tener en cuenta que se deben dar permisos a las funciones lambda para que éstas puedan insertar datos en Kinesis.
En este caso, se le añadió la siguiente política al rol establecido para la función:

Crear un proceso almacenado y un trigger en la base de datos de Aurora.
Con el trigger se identificarán todos los casos en los que se estén modificando los datos en Aurora, éste los captará y llamará al proceso almacenado, el cual se encargará de invocar al siguiente componente del proceso: la función Lambda.
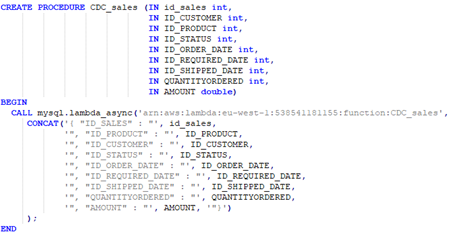
En el siguiente ejemplo se puede ver como el trigger TR_f_sales_CDC se encarga de captar todos los datos de las filas que se van a insertar por primera vez en la base de datos e invoca al proceso almacenado CDC_sales pasándole por parámetro todos los campos de datos.
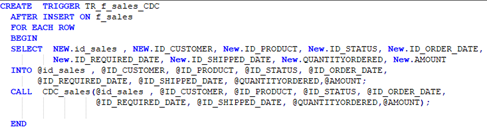
En el proceso almacenado CDC_sales se recogen todos los campos de datos y se invoca a la función lambda de forma asíncrona.
En los parámetros de la invocación de la función lambda está el ARN de la función (su identificador) y los campos de datos recibidos concatenados para poder ser tratados por la función lambda. Esto se hace porque los datos que se pasan por parámetro en la invocación de la función lambda deben estar en el formato Json, y como desde SQL no se puede generar ficheros Json, se deben tratar los datos de esta manera.
Otra posibilidad es la de invocar a la función lambda directamente desde el trigger.
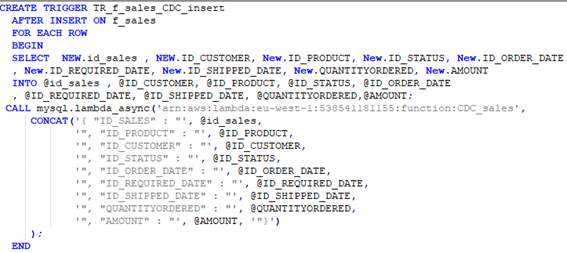
Las capturas mostradas son del trigger que registra las nuevas inserciones, pero también deben crearse otros triggers para las situaciones en las que se eliminen registros o se modifiquen.
Un aspecto que se debe tener en cuenta es que deben darse permiso a la base de datos para la invocación de la función lambda. Para ello, entre los roles IAM que deben habilitarse tiene que estar el rol “AllowAuroraLambdaRole”.

Bloqueo de tablas
Cuando un trigger salta tras la inserción, modificación o eliminación de algún registro, automáticamente se bloquea la tabla para evitar problemas de consistencia de datos. Este factor condiciona a que durante el periodo en el que se esté ejecutando el trigger, no se podrá realizar ninguna actividad sobre esta tabla.
Precios de las diferentes soluciones
AWS Lambda imputa en su precio tanto el número de veces que se solicita cada función lambda como la duración (medida en GB/s) que ésta tiene desde que empieza su ejecución hasta que finaliza.
AWS tiene tres planes de cobro para esta solución:
· Versión gratuita: Versión que permite la invocación de la función un millón de veces y una capacidad de cómputo de 400000GB/s gratis al mes.
· Versión de pago: En esta versión, el servicio cobra 0.20$ por caca millón de solicitudes y 0.0000166667$ por cada GB/s utilizado. Los precios pueden cambiar dependiendo del volumen de memoria que se desee contratar[1].
· Saving Plans: Plan de pago que ofrece precios más económicos para el uso de aws lambda, a cambio de comprometerse a un uso determinado constante (medido en USD/hora) durante el término de 1 o 3 años.
En Amazon Kinesis Data Firehose los precios dependen del volumen de datos recibido en la herramienta, que se calcula multiplicando la cantidad de registros de datos enviados al servicio, por el tamaño de cada registro, redondeado hacia arriba hasta el múltiplo de 5 KB (5120 bytes) más cercano[2].
En Amazon S3, la tasa que se cobra depende del tamaño de los objetos, la cantidad de tiempo que se almacenan al mes y la clase de almacenamiento utilizada
CDC utilizando DEBEZIUM
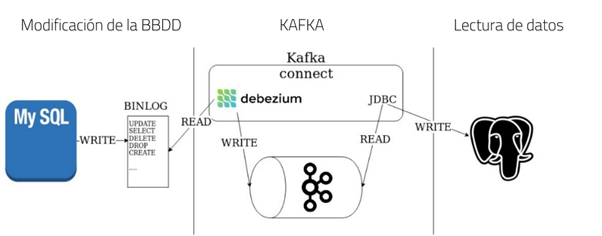
Debezium es una herramienta que realiza funciones de CDC proporcionando una plataforma de streaming de datos de baja latencia para capturar cambios en los datos. La herramienta utiliza las herramientas de Kafka y Kafka Connect para conectarse a los orígenes de datos y que todos los eventos registrados queden ordenados y preparados para ser consumidos por los clientes.
Las características de Debezium son muy similares a las de otras herramientas con la misma funcionalidad. De entre todas las características hay que destacar:
· Monitorización de un conjunto heterogéneo de bases de datos generando una salida estandarizada para cada una de ellas, algo que facilita la administración y manejo de todos los eventos.
· En caso de detenerse la herramienta, al reiniciarse se registrarán todos los eventos que se produjeron en el periodo de tiempo en el que Debezium estuviese apagado.
· Si el cliente se desconectase de Debezium, al volver a establecer conexión, éste recibiría toda la información de los eventos sucedidos en el periodo de tiempo que duró la desconexión.
|
Git clone https://github.com/debezium/debezium.git |
Para instalar la herramienta en la máquina lo único que se debe hacer es descargar el código fuente de GitHub en el ordenador. Esto se puede hacer con el comando anterior
Conectar Debezium a una base de datos Aurora MySQL
Para ejecutar Debezium es necesario activar tres plataformas que se montarán sobre tres dockers diferentes: Zookeeper, Kafka y Kafka Connect. Por ello, lo primero que se debe hacer es ejecutar Docker Engine (en Windows se llama Docker Desktop).
Arrancar Zookeeper
El primer paso es arrancar Zookeeper, una herramienta de Apache que ofrece un servicio de coordinación de procesos. Para ello, se debe abrir una terminal de Windows o Linux y ejecutar el siguiente comando:
|
docker run -it --rm --name zookeeper -p 2181:2181 -p 2888:2888
-p 3888:3888 debezium/zookeeper:1.0 |
Con este comando se descargará la imagen de Zookeeper y posteriormente ésta se ejecutará automáticamente.
Para comprobar que se haya ejecutado correctamente, se deben buscar los siguientes logs:
|
Starting up in standalone mode ZooKeeper JMX enabled by default Using config: /zookeeper/conf/zoo.cfg 2017-09-21 07:15:55,417 - INFO [main:QuorumPeerConfig@134]
-Reading configuration from: /zookeeper/conf/zoo.cfg 2017-09-21 07:15:55,419 - INFO
[main:DatadirCleanupManager@78] -autopurge.snapRetainCount set to 3 2017-09-21 07:15:55,419 - INFO
[main:DatadirCleanupManager@79] -autopurge.purgeInterval set to 1 ... port 0.0.0.0/0.0.0.0:2181 |
Arrancar Kafka
Una vez esté iniciado Zookeper, el siguiente paso es arrancar Kafka, una plataforma de alto rendimiento y de baja latencia para la manipulación en tiempo real de fuentes de datos que será utilizada como cola donde almacenar los mensajes relativos a los eventos en la base de datos. Para ello se debe abrir una nueva terminal en la que introducir el siguiente comando:
|
docker run -it --rm --name kafka -p 9092:9092 --link
zookeeper:zookeeper debezium/kafka:1.0 |
Al igual que en el paso anterior, con este comando se descargará la imagen de Kafka y posteriormente ésta se ejecutará automáticamente.
|
... 2017-09-21 07:16:59,085 - INFO [main-EventThread:ZkClient@713]
-zookeeper state changed (SyncConnected) 2017-09-21 07:16:59,218 - INFO [main:Logging$class@70] -Cluster ID =
LPtcBFxzRvOzDSXhc6AamA ... 2017-09-21 07:16:59,649 - INFO [main:Logging$class@70] -[Kafka Server
1], started |
Para comprobar que se haya ejecutado correctamente, se deben buscar los siguientes logs:
Arrancar Kafka Connect
Una vez esté iniciado Kafka, el siguiente paso es arrancar Kafka Connect, que en Debezium es utilizado como Framework para conectar y exportar los datos del binary log de la base de datos y enviarlos a Kafka.
|
docker run -it
--rm --name connect -p 8083:8083 -e GROUP_ID=1 -e
CONFIG_STORAGE_TOPIC=my_connect_configs -e
OFFSET_STORAGE_TOPIC=my_connect_offsets -e
STATUS_STORAGE_TOPIC=my_connect_statuses --link zookeeper:zookeeper --link
kafka:kafka debezium/connect:1.0 |
Para ello se debe abrir una nueva terminal en la que introducir el siguiente comando:
Al igual que en los pasos anteriores, con este comando se descargará la imagen de Kafka Connect y posteriormente ésta se ejecutará automáticamente.
Para comprobar que se haya ejecutado correctamente, se deben buscar los siguientes logs:
|
... 2020-02-06 15:48:33,939 INFO ||
Kafka version: 2.4.0
[org.apache.kafka.common.utils.AppInfoParser] ... 2020-02-06 15:48:34,485 INFO ||
[Worker clientId=connect-1, groupId=1] Starting connectors and tasks
using config offset -1 [org.apache.kafka.connect.runtime.distributed.DistributedHerder] 2020-02-06 15:48:34,485 INFO ||
[Worker clientId=connect-1, groupId=1] Finished starting connectors
and tasks [org.apache.kafka.connect.runtime.distributed.DistributedHerder] |
Para comprobar que este modulo se ha instalado bien se puede abrir otra terminal y ejecutar el siguiente comando:
|
curl -H "Accept:application/json" localhost:8083/ |
Éste debería devolver una salida parecida a la siguiente:
{"version":"2.4.0","commit":"77a89fcf8d7fa018","kafka_cluster_id":"SP1wTIUoS4q9ttSRT18jDA"}
Desplegar el conector Mysql
Para desplegar el conector, se va a realizar una petición HTTP a Kafka Connect enviando la configuración del mismo. La estructura de la configuración a enviar es la siguiente:
|
{ "name":
"Nombre del conector", "config":
{ "connector.class":
"io.debezium.connector.mysql.MySqlConnector", "tasks.max":
"1", "database.hostname":
"Host de la base de datos", "database.port":
"Puerto de conexion", "database.user":
"Usuario", "database.password":
"Contraseña", "database.server.id":
"184054", "database.server.name":
"dbserver1", "database.whitelist":
"Nombre de la base de datos", "database.history.kafka.bootstrap.servers":
"kafka:9092", "database.history.kafka.topic":
"schema-changes.nombre_BD" } } |
Para la realización de la petición del conector se debe ejecutar el siguiente comando “curl” sustituyendo los parámetros (en rojo) por los necesarios para establecer conexión con la base de datos deseada.
Nota: Esta consulta está preparada para ser ejecutada en línea de comandos desde una terminal de Linux, si se desease realizar con una terminal Windows habría que cambiar el formato para adaptar la consulta a la sintaxis de Windows.
|
curl -i -X POST -H 'Accept: application/json' -H 'Content-Type:
application/json' 'http://localhost:8083/connectors/' -d '{
"name": "Nombre del conector",
"config": { "connector.class":
"io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1", "database.hostname": "Host de la Base de datos",
"database.port": "Puerto de conexión",
"database.user": "Usuario",
"database.password": "Contraseña",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.whitelist": "Nombre de la base
de datos",
"database.history.kafka.bootstrap.servers":
"kafka:9092", "database.history.kafka.topic":
"dbhistory.nombre_BD" } }' |
Un aspecto a tener en cuenta es que los parámetros de la conexión se deben escribir tal y como son, ya que es case sensitive, esto es que es sensible a mayúsculas y minúsculas y por tanto, cualquier error de inserción puede hacer que la conexión falle.
Visualizar los cambios en la base de datos
Para visualizar los cambios que se han capturado, se deben extraer los logs del topic de Kafka en el que estén almacenados. Para ver que los cambios se han registrado en este caso de uso se ha utilizado “watch-topic”. Para ello se ha utilizado una nueva ventana en la que se ha ejecutado el siguiente comando.
|
docker run -it --rm --name watcher --link zookeeper:zookeeper
--link kafka:kafka debezium/kafka:1.0 watch-topic -a -k dbserver1.nombre_db.tabla |
Para la ejecución del comando hay que sustituir los parámetros (en rojo) por los necesarios para buscar los cambios realizados en una tabla específica de la base de datos.
Requisitos y consideraciones a tener en cuenta
Requisitos en la instalación de Debezium
En referencia a la herramienta, para poder usar Debezium es necesario que la máquina donde se va a instalar Debezium cuente con las siguientes herramientas:
· Git 2.2.1 o superior.
· JDK 8 u OpenJDK 8
· Docker Enigine 1.9 o superior
Por lo tanto, los requisitos de hardware necesarios para instalar Debezium son los requisitos de estos componentes. Estos son:
ü Para instalar Docker en Windows es necesario tener Windows 10 Pro, Enterprise o Education; tener activado WSL 2 o Hyper-V y tener al menos 4GB de RAM.
ü Para instalar JDK8 una RAM mínima de 128 MB y un espacio mínimo en disco de 124 MB para el JRE y 2 MB para Java Update.
Requisitos en la base de datos
La extracción de los eventos se realiza mediante consultas al registro binario (BinLog) de la base de datos, que es el fichero de log que registra todos los cambios de datos que se han realizado. Es por ello que la base de datos tenga activado el parámetro binary log a nivel de fila[1].
Bloqueos de las tablas
Habitualmente Debezium utiliza el bloqueo global de la base de datos para la realización de las consultas al registro binario.
En las bases de datos de Amazon Aurora y Amazon RDS no está permitido este tipo de bloqueo, por lo que Debezium utiliza bloqueos a nivel de tabla para asegurar que las capturas que realiza son consistentes.
Debezium en entornos de producción
Como ya se ha visto anteriormente, Debezium utiliza Kafka Connect para establecer conexión con la base de datos, extraer del registro BinLog toda la información acerca de los cambios de datos y enviarla a Kafka. Posteriormente, desde Kafka se pueden establecer canales de lectura que permitan extraer la información a herramientas cliente.
Esta configuración es la más simple que se puede implementar.
Para conseguir una alta disponibilidad en Kafka se podría añadir un nodo secundario que sustituiría al nodo primario en el caso en el que éste se desconectase. Esto significaría que si esta situación ocurriese, el cliente tendría que conectarse al nodo secundario para obtener los cambios.
Esta solución requiere reconfigurar el conector para que los datos vayan al nuevo nodo primario. Para evitar realizarlo manualmente, se suele utilizar un proxy que permita la conmutación entre nodos de manera automática.
Si en la configuración básica el conector estuviese indisponible un tiempo no habría problemas de captura de datos, pues al volverse a conectar, este leería los datos del binlog a partir del último registro que se leyó. Pero es posible que se desee tener alta disponibilidad también en el conector. Para ello se necesitaría ejecutar dos instancias de Debezium que estén conectadas a la misma base de datos. Esto haría que no existiese tiempo de inactividad en la captura de datos, pero por contrapartida se cada evento está almacenado dos veces y se podrá llegar a tener problemas de duplicidad de datos si no se controla qué eventos se han leído desde el cliente final y cuáles no.
Comparativa de rendimiento
Se ha realizado una comparativa de rendimiento para ver qué solución es menos intrusiva a la hora de hacer los bloqueos en las tablas.
Para esta comparativa se ha trabajado con 384 nuevos registros que han sido insertados, modificados y eliminados de la base de datos para medir el tiempo que tardaba ésta en realizar las diferentes acciones. De esta manera se puede conocer el tiempo que dura el bloqueo de las tablas con las que se ha trabajado.
Los resultados de las pruebas son los siguientes:
Tiempos de ejecución con Debezium:
· insertar: 105 ms
· modificar: 130 ms
· borrar: 99 ms
Tiempos de ejecución con herramientas AWS:
· insertar: 15.622 s
· modificar: 15.584 s
· borrar: 17.26 s
Esta diferencia de tiempos se debe a que, mientras que la captura de datos del log_bin que hace Debezium se realiza en un solo paso, la captura de datos con las herramientas de AWS requiere de un trigger que salte por cada evento, lo que hace que el bloqueo de las tablas sea mucho mayor.
Por todo ello, el rendimiento que ofrece Debezium es mucho mayor que el rendimiento obtenido con las herramientas de AWS.
Descarga este paper gratuito para saber más sobre herramientas CDC

Existen varias soluciones de CDC: Maxwell, SpinalTap, Yelp’s MySQL Streamer, Debezium, DBLog…
Nos centraremos en una de estas soluciones, que a nuestro punto de vista es la más simple de utilizar: Debezium
Debezium es una herramienta que realiza funciones de CDC (Change Data Capture) proporcionando una plataforma de streaming de datos de baja latencia para capturar cambios en los datos. Reutiliza las herramientas Kafka y Kafka Connect, con lo que consigue agregar varias conexiones de bases de datos y que todos los eventos queden bien ordenados para que varios clientes puedan consumirlos sin afectar demasiado la captura de los eventos. Posee las características comunes de una herramienta CDC. Entre ellas, destaca:
· Puede monitorizar un conjunto heterogéneo de bases de datos, produciendo una salida estandarizada independientemente de la base de datos en la que se produjo el cambio, lo que facilita bastante la administración y manejo de los cambios.
· Debezium es tolerante a fallos: si por algún motivo Debezium se detuviera, al reiniciarse registrará los cambios que se produjeron mientras estaba apagado para asegurar que todos los eventos se registran y procesan adecuadamente. Adicionalmente, agrega esta característica pero para el lado del cliente, es decir, si un cliente se desconecta del servicio, cuando se vuelva a conectar recibirá todos los eventos que sucedieron mientras estaba desconectado.
Debezium proporciona multitud de módulos para conexión con bases de datos. Algunos de ellos son genéricos, para soportar cualquier base de datos, con la desventaja de que son algo limitados; y otros son específicos de algunas bases de datos. En concreto, Debezium proporciona conectores con bases de datos MySQL, PostgreSQL, MongoDB y SQL Server. Además, se está desarrollando conectores para Oracle, Cassandra y Db2. Estos tres últimos se pueden emplear pero al estar en desarrollo, podrían estar sujetos a cambios.