Os hemos venido contando bastante de Vertica en TodoBI y no nos cansamos de recomendar esta espectacular Base de Datos analítica
Hoy os traemos algunos trucos para sacarle todo el partido
Proyecciones:
Dentro de la base de datos de Vertica, las tablas se mantienen como un concepto lógico. Aunque los datos no se almacenan en tablas, este concepto facilita al usuario el uso de consultas SQL estándar contra la base de datos sin tener que aprender un nuevo lenguaje. Para cada tabla, Vertica crea una o más proyecciones físicas. Aquí es donde los datos se almacenan en el disco, en un formato optimizado para la ejecución de la consulta. Cada proyección contiene un subconjunto de las columnas de una tabla, pero esas columnas no necesariamente están en el mismo orden que se muestra en la tabla. Los datos de cada proyección también pueden ser ordenados de manera diferente entre sí y por el orden de clasificación de la tabla.
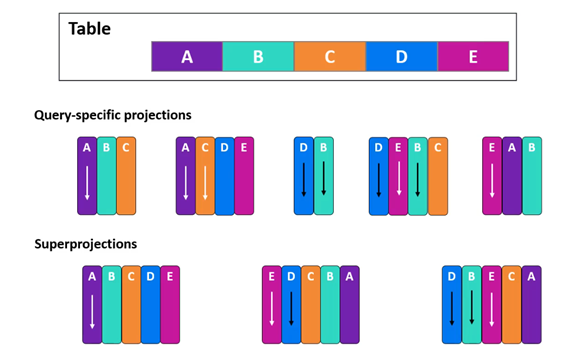
Hay dos tipos básicos de proyección que pueden crearse a partir de una tabla base. Si se realizan consultas frecuentes, se pueden construir proyecciones específicas para esas consultas, dichas proyecciones específicas de consultas son proyecciones que contienen un subconjunto de las columnas de la tabla base. Las columnas se eligen para mejorar el rendimiento de las consultas más frecuentes. Vertica elegirá automáticamente la proyección que mejor se ajuste a la consulta. Dependiendo del número y tipos de consultas que se ejecuten, se puede esperar que Vertica cree entre 2 y 5 proyecciones específicas por tabla base. ¿Pero qué pasa si necesitas ejecutar una consulta ad-hoc? Para cada tabla, Vertica también crea al menos una superproyección. Las superproyecciones contienen cada columna de la tabla y cada una de ellas puede clasificar la información de forma diferente en función de los tipos de consultas ad-hoc que esperas.
En la siguiente imagen se muestran tres posibles superproyecciones que pueden ser creadas a partir de la tabla base. Mientras que cada una de estas proyecciones contiene todas las columnas que están en la tabla base, el orden de las columnas es diferente, así como las columnas utilizadas para ordenar los datos. En un entorno típico, Vertica creará una o dos superproyecciones por tabla base.
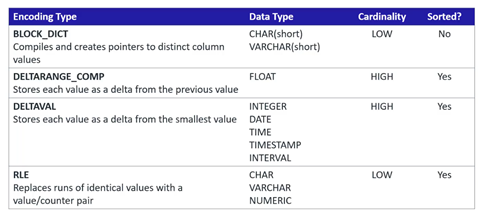
Vertica codifica y comprime los datos en las columnas de proyección para aumentar el rendimiento de la consulta, reduciendo la IO del disco. Los métodos de codificación y compresión dependen del tipo de datos, de la cardinalidad de los datos y de si los datos han sido clasificados.
Esto permite a Vertica optimizar el rendimiento de las consultas y ahorrar espacio de almacenamiento. A continuación se muestran los tipos de codificación más utilizados.
Para la distribución de los datos en las proyecciones almacenadas en cada uno de los nodos, se disponen de dos métodos. Por un lado, la replicación de proyecciones hace una copia completa de la proyección y colocan estas copias idénticas en todos los nodos del cluster. Se utiliza para proyecciones pequeñas y es útil cuando hay una unión. Al tener los datos de cada nodo, la unión puede ocurrir localmente. Si un nodo del cluster se cae, los otros nodos pueden seguir procesando la consulta, lo que permite una alta disponibilidad de la base de datos.
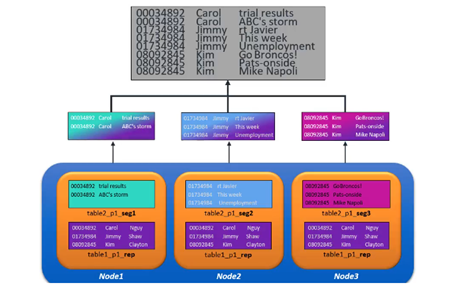
Por otro lado, la segmentación de las proyecciones distribuye uniformemente los datos de las grandes proyecciones entre los nodos del conglomerado y suele estar diseñada para ser lo más aleatoria posible. En cada nodo se almacena un segmento de los datos de la proyección, de modo que todos los nodos pueden participar por igual en la ejecución de la consulta y se distribuye la carga de trabajo de la ejecución de la consulta entre varios nodos. Las consultas que hacen referencia a proyecciones segmentadas y replicadas permiten un procesamiento distribuido, de modo que ningún nodo tiene que hacer toda la respuesta de la consulta trabajo.
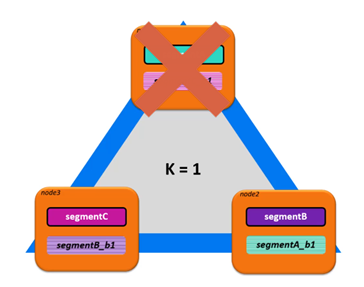
Vertica está diseñada para una alta disponibilidad, es decir, la capacidad de la base de datos para seguir funcionando incluso si un nodo se cae. Al crear la base de datos, se establece el nivel deseado de tolerancia a fallos en 0, 1 o 2. Esto se conoce como el nivel de k-safe.
En el siguiente ejemplo podemos ver un cluster de 3 nodos con un nivel de k-safe igual a 1. Vertica crea copias K de cada segmento de proyección, como k-safe para este grupo es uno, sólo se hará una copia. Cada una de estas copias se almacena en el nodo vecino del cluster. Si uno de los nodos se cae temporalmente, su base de datos seguirá siendo funcional hasta que se recupere porque los datos de cada segmento todavía están disponibles en otro nodo. Mientras su base de datos siga funcionando, no es óptimamente funcional. En este ejemplo, el nodo dos está haciendo el doble de trabajo para responder a las consultas hasta que el nodo uno se recupere.