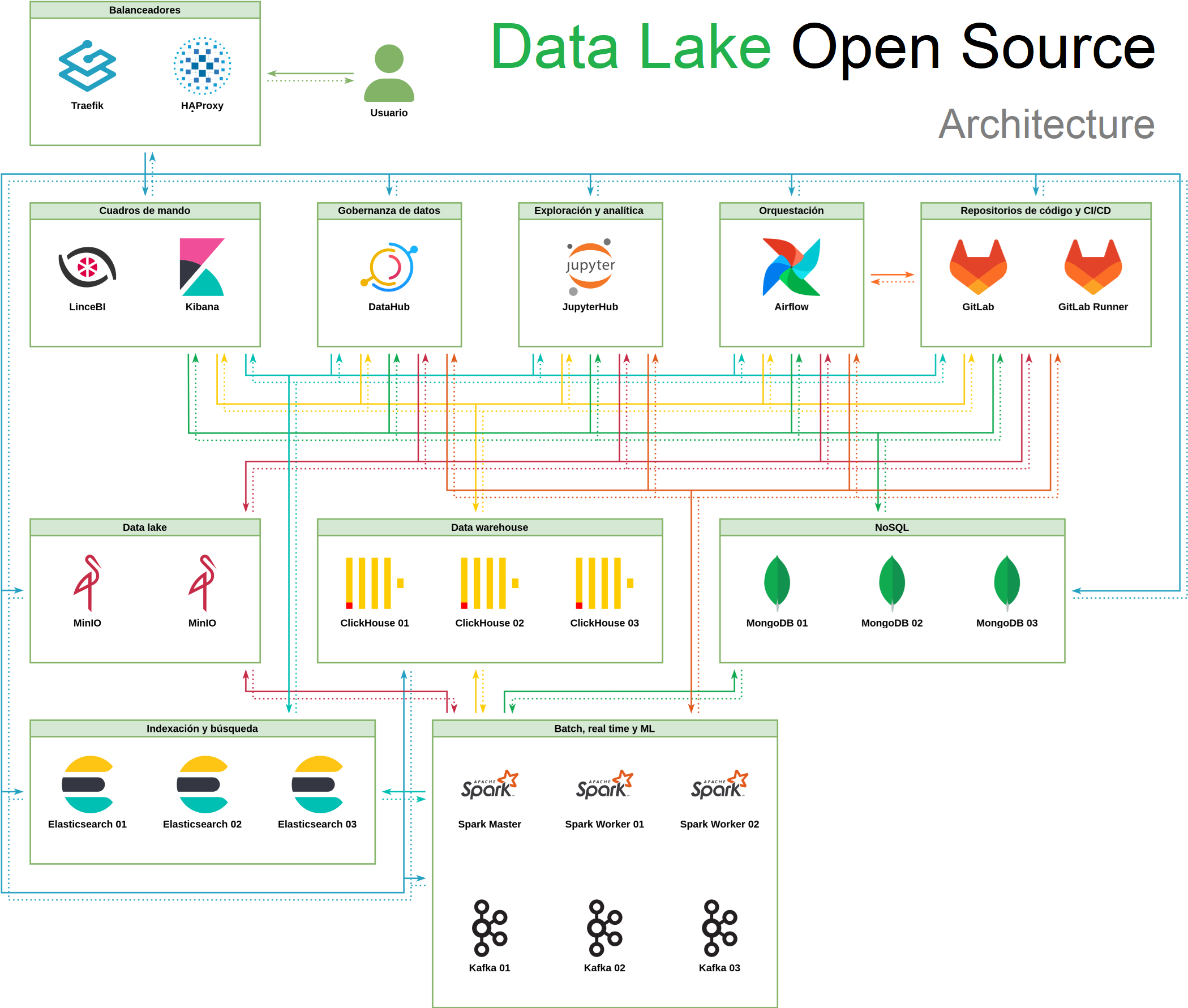
🚀 Cómo es la arquitectura de un completo '𝗗𝗮𝘁𝗮 𝗟𝗮𝗸𝗲 𝗢𝗽𝗲𝗻 𝗦𝗼𝘂𝗿𝗰𝗲', con todas sus herramientas!!
🔎 En una arquitectura tecnológica moderna de un Data Lake, éste debe permitir la ingesta, integración, almacenamiento y explotación de cualquier tipo de fuentes de datos
Cada vez, más, las organizaciones están apostando por soluciones 'open source' en donde existe un importante soporte de la comunidad que facilita su uso y garantiza la continuidad de las herramientas a largo plazo.
𝗔𝗥𝗤𝗨𝗜𝗧𝗘𝗖𝗧𝗨𝗥𝗔:
✅ Con entornos de 𝗣𝗿𝗼𝗱𝘂𝗰𝗰𝗶𝗼́𝗻, 𝗣𝗿𝗲𝗽𝗿𝗼𝗱𝘂𝗰𝗰𝗶𝗼́𝗻 𝘆 𝗗𝗲𝘀𝗮𝗿𝗿𝗼𝗹𝗹𝗼
✅ Esta Arquitectura es un 𝗰𝗮𝘀𝗼 𝗿𝗲𝗮𝗹 implementado para una gran administración pública en el que he participado
✅ Instalado, preparado y configurado con 𝗗𝗼𝗰𝗸𝗲𝗿 𝗖𝗼𝗺𝗽𝗼𝘀𝗲 y seguridad común integrada
✅ El sistema operativo sobre el que funciona la infraestructura es 𝗨𝗯𝘂𝗻𝘁𝘂 22.04
✅ La aplicación automática de actualizaciones está activa mediante 𝘂𝗻𝗮𝘁𝘁𝗲𝗻𝗱𝗲𝗱-𝘂𝗽𝗴𝗿𝗮𝗱𝗲𝘀
✅ El firewall utilizado en los servidores es 𝗻𝗳𝘁𝗮𝗯𝗹𝗲𝘀
✅ Se ha configurado el servidor de 𝗢𝗽𝗲𝗻𝗦𝗦𝗛
✅ Se usa 𝗧𝗿𝗮𝗲𝗳𝗶𝗸 como Proxy inverso encargado de la terminación TLS y balancear la carga de los servicios desplegados en clúster
✅ También se configura 𝗛𝗔𝗣𝗿𝗼𝘅𝘆, como Proxy inverso secundario encargado del HA de MongoDB
✅ Para la creación de Cuadros de Mando, Informes y Analytics se usa 𝗟𝗶𝗻𝗰𝗲𝗕𝗜
✅ Para la explotación del uso de Elasticsearch se configura 𝗞𝗶𝗯𝗮𝗻𝗮 como Interfaz
✅ Para el Gobierno de Datos usamos 𝗗𝗮𝘁𝗮𝗛𝘂𝗯
✅ 𝗝𝘂𝗽𝘆𝘁𝗲𝗿𝗛𝘂𝗯 está configurada con un Docker Spawner personalizado que añade integración con Spark
✅ Para la Orquestación de ingestas, usamos 𝗔𝗽𝗮𝗰𝗵𝗲 𝗔𝗶𝗿𝗳𝗹𝗼𝘄. La aplicación está desplegada con una imagen de Docker personalizada basada en la imagen oficial, se añaden múltiples conectores entre los que se destacan el soporte para ClickHouse, MongoDB, Spark y Kafka
✅ Como repositorios de código y CI/CD se usa 𝗚𝗶𝘁𝗹𝗮𝗯. La aplicación está configurada con LDAP
✅ Para la getión del Data Lake se ua 𝗠𝗶𝗻𝗜𝗢, que está desplegado en 2 nodos
✅ Para el almacenamiento y Base de Datos del Data Lake se usa 𝗖𝗹𝗶𝗰𝗸𝗵𝗼𝘂𝘀𝗲 que está desplegado en 1 shard con 3 réplicas
✅ Para la gestión del almacenamiento NoSQL usamos 𝗠𝗼𝗻𝗴𝗼𝗗𝗕 que está desplegado en 1 replica set con 3 miembros
✅ Para agilizar y potenciar la indexación y búsqueda, se usa 𝗘𝗹𝗮𝘀𝘁𝗶𝗰𝘀𝗲𝗮𝗿𝗰𝗵
✅ Para el procesamiento de los 'data pipelines' en Batch, Real Time y Machine Learning usamos 𝗦𝗽𝗮𝗿𝗸. El nodo con Spark Master lleva incluido Spark Connect y un worker, el resto de nodos únicamente llevan un worker
✅ 𝗞𝗮𝗳𝗸𝗮 está desplegado con 3 nodos controller y broker que usan KRaft como protocolo de consenso
Arquitectura 'Data Lake Open Source'