


Una vez más, ponemos el radar para iros contando que tecnologías de datos debes tener en cuenta este año, que están emergiendo y consolidándose. Quizás, deberías ir evaluando:
Como siempre, puedes escribirme (administrador@todobi.com) si necesitas ayuda o apoyo con estos proyectos
1. PyTorch
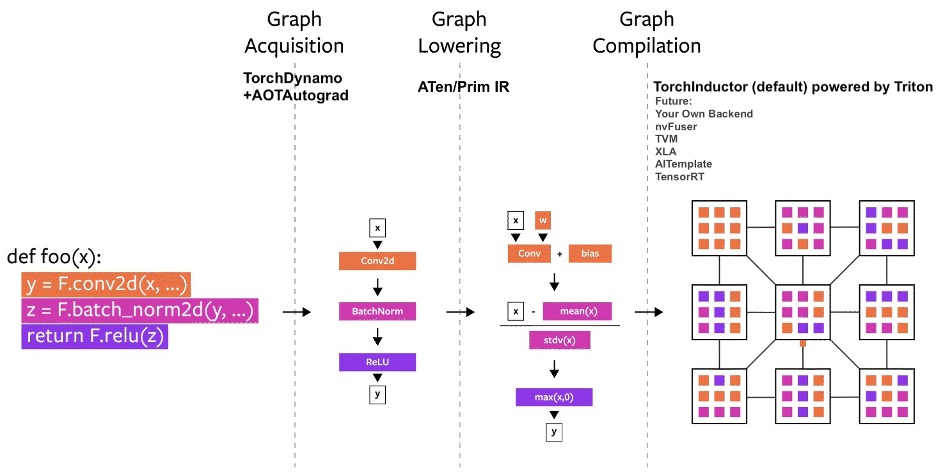
PyTorch ha consolidado su posición como uno de los proyectos de software de aprendizaje automático más importantes y exitosos del panorama del código abierto.
PyTorch 2.0 se lanzó en diciembre de 2022 en la Conferencia inaugural de PyTorch, con enormes mejoras de rendimiento y nuevas integraciones. Uno de los aspectos más destacados es torch.compile, que traslada los operadores de C++ a Python para mejorar el rendimiento y la flexibilidad.
2. Ibis
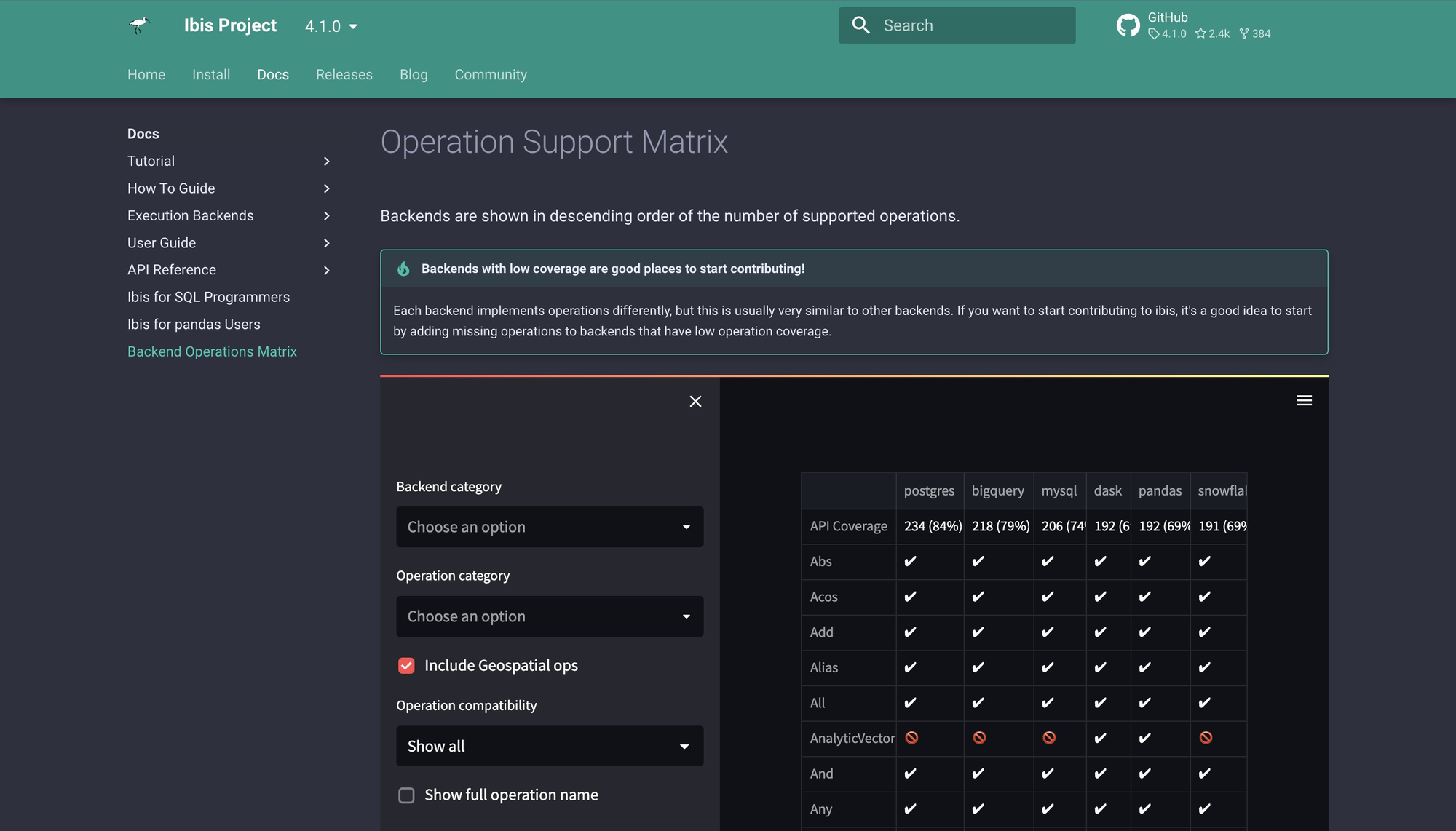
Ibis es un marco modular que ayuda a los desarrolladores a conectar, transformar y extraer datos que pueden representarse como datos tabulares.
Las descargas del proyecto se han disparado en los dos últimos años, y puede que esté en camino de convertirse en la herramienta estándar para los usuarios que trabajan con datos tabulares.
El lanzamiento de Ibis 4.0 está previsto para enero de 2023. Con él llegarán funciones como la API de lectura, que permite a los usuarios leer rápidamente archivos de datos tabulares (CSV, Parquet, texto) para realizar análisis exploratorios rápidos con DuckDB, y los métodos to_pyarrow, que permiten a los usuarios enviar conjuntos de resultados a tipos pyarrow (como Tables y RecordBatches).
3. Velox
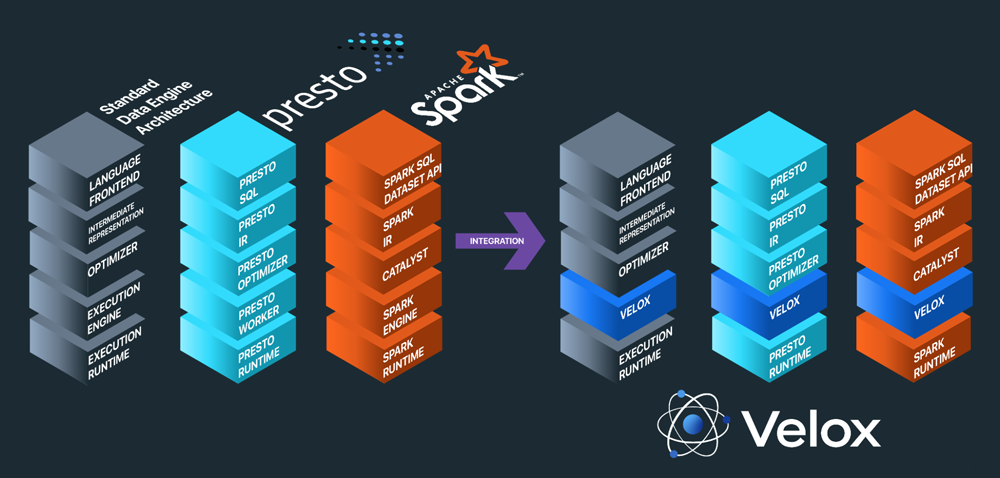
Fue lanzado por Meta en agosto de 2022 con contribuciones de Ahana, Intel. etc... Velox utiliza una disposición de memoria compatible con Apache Arrow y está diseñado para acelerar los sistemas de gestión de datos y agilizar el desarrollo. Aborda la ingeniería de características, el preprocesamiento de datos y otros casos de uso de la inteligencia artificial (IA) y el aprendizaje automático (ML) en rápido crecimiento.
Lo que es importante destacar es que Velox está construido desde cero para funcionar en CPUs modernas.
Velox centraliza la computación, ayudando a los ingenieros a conectar con los motores más rápidamente para que puedan centrar sus esfuerzos en los resultados (para sus aplicaciones, casos de uso y clientes) en lugar de reinventar la rueda en esfuerzos a medida.
- Velox on GitHub
- A introductory talk by Pedro Pedreira, Software Engineer at Meta: "Velox: An Open Source Unified Execution Engine"
- Blog: "Introducing Velox: An open source unified execution engine"
4. Airflow
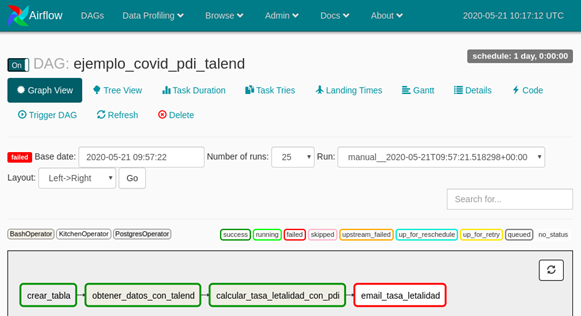
Apache Airflow es una herramienta de orquestación que permite crear, programar y monitorizar flujos de trabajo mediante programación en Python.
Estos flujos de trabajos se representan como Grafos Acíclicos Dirigidos o DAGs (del inglés Directed Acyclic Graph) de tareas / procesos, es decir grafos donde los datos fluyen en una sola dirección entre los procesos, por lo que si algún trabajo X falla, los trabajos que dependen del trabajo X no se ejecutan
Permite la creación, programación y monitorización centralizada de flujos de trabajos complejos que se conectan a varios backends. Código personalizado para la lógica de reintentos cuando una tarea falla
Orquestación estandarizada de ETLs. Permite trabajar con herramientas ETL como Pentaho Data Integration y Talend
- Airflow home page
- En este enlace, puedes descargarte el paper de Introducción a Apache Airflow, en español, explicando la configuración y con casos de uso
5. DuckDB

DuckDB es de las novedades más interesantes. A menudo se describe como un SQLite para flujos de trabajo analíticos, pero ofrece almacenamiento de datos integrable y orientado a columnas que utiliza procesamiento vectorizado para optimizar las cargas de trabajo OLAP.
Nos gusta que el proyecto ofrezca una integración de datos de copia cero con Apache Arrow, lo que permite un análisis rápido de conjuntos de datos más grandes que la memoria.
Los desarrolladores están adoptando DuckDB porque es fácil de instalar, ligero y proporciona análisis rápidos. El stack se basa en la CPU y está diseñada para un único nodo. Como también simplifica la integración de bibliotecas de lenguajes, estamos viendo cómo atrae a usuarios de otros sistemas de bases de datos relacionales tradicionales, como MySQL y Postgres.
6. Rapids
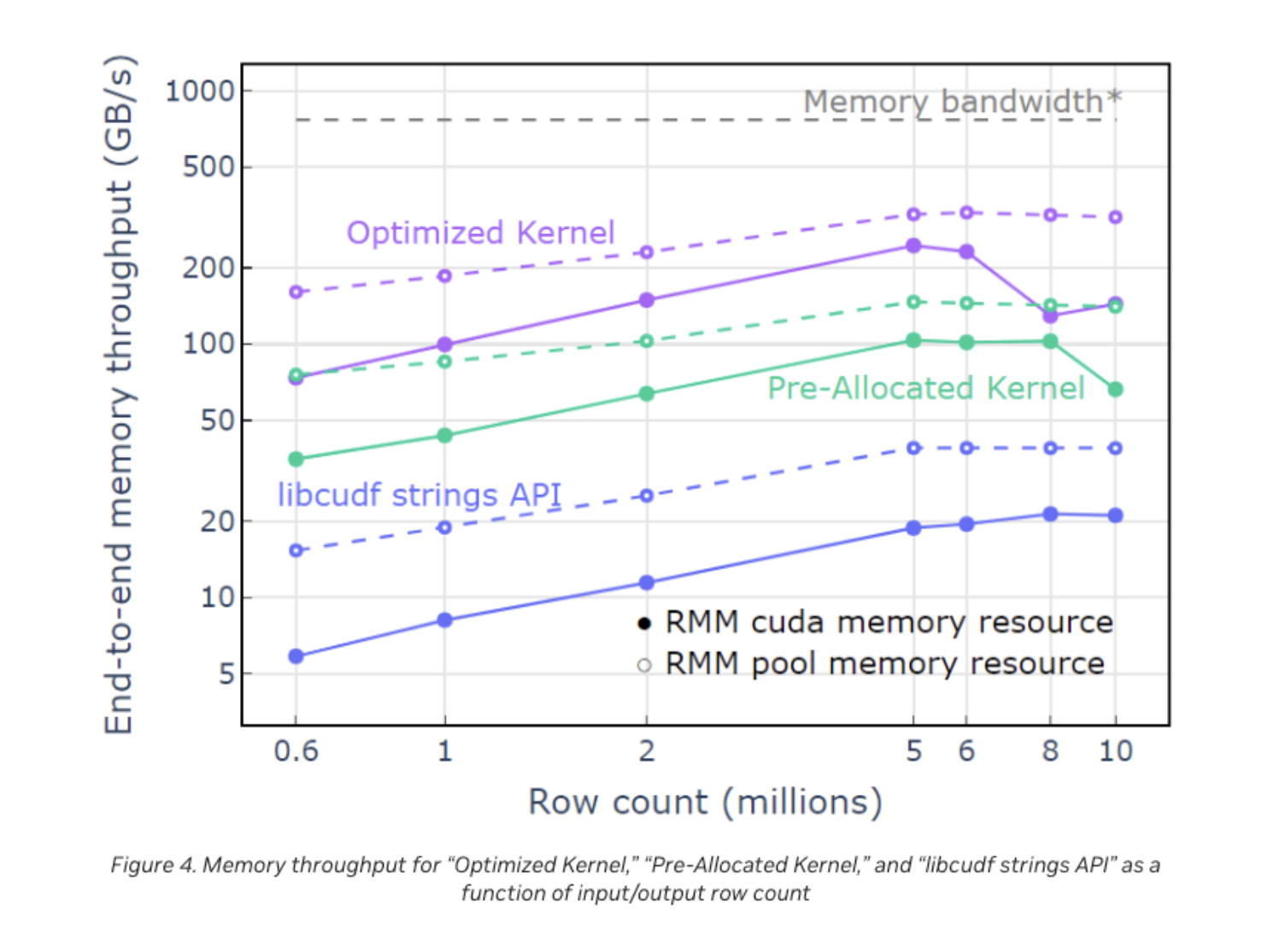
RAPIDS es una colección de librerías de código abierto de análisis, aprendizaje automático, análisis de gráficos y visualización que utilizan interfaces Pythonic para exponer primitivas C++ para optimizaciones de cálculo de bajo nivel en las GPU NVIDIA.
En esencia, la librería de marcos de datos C++ de RAPIDS, libcuDF, es nativa de Arrow y está diseñada desde cero para aprovechar el formato de datos en memoria en columnas de Arrow y proporcionar un intercambio de datos rápido y eficaz.
Para los ingenieros y arquitectos de datos, RAPIDS permitió la compresión zstd en lectores y escritores ORC y Parquet. Cada vez son más las empresas que adoptan Zstandard como forma de comprimir sus datos almacenados.
7. Substrait
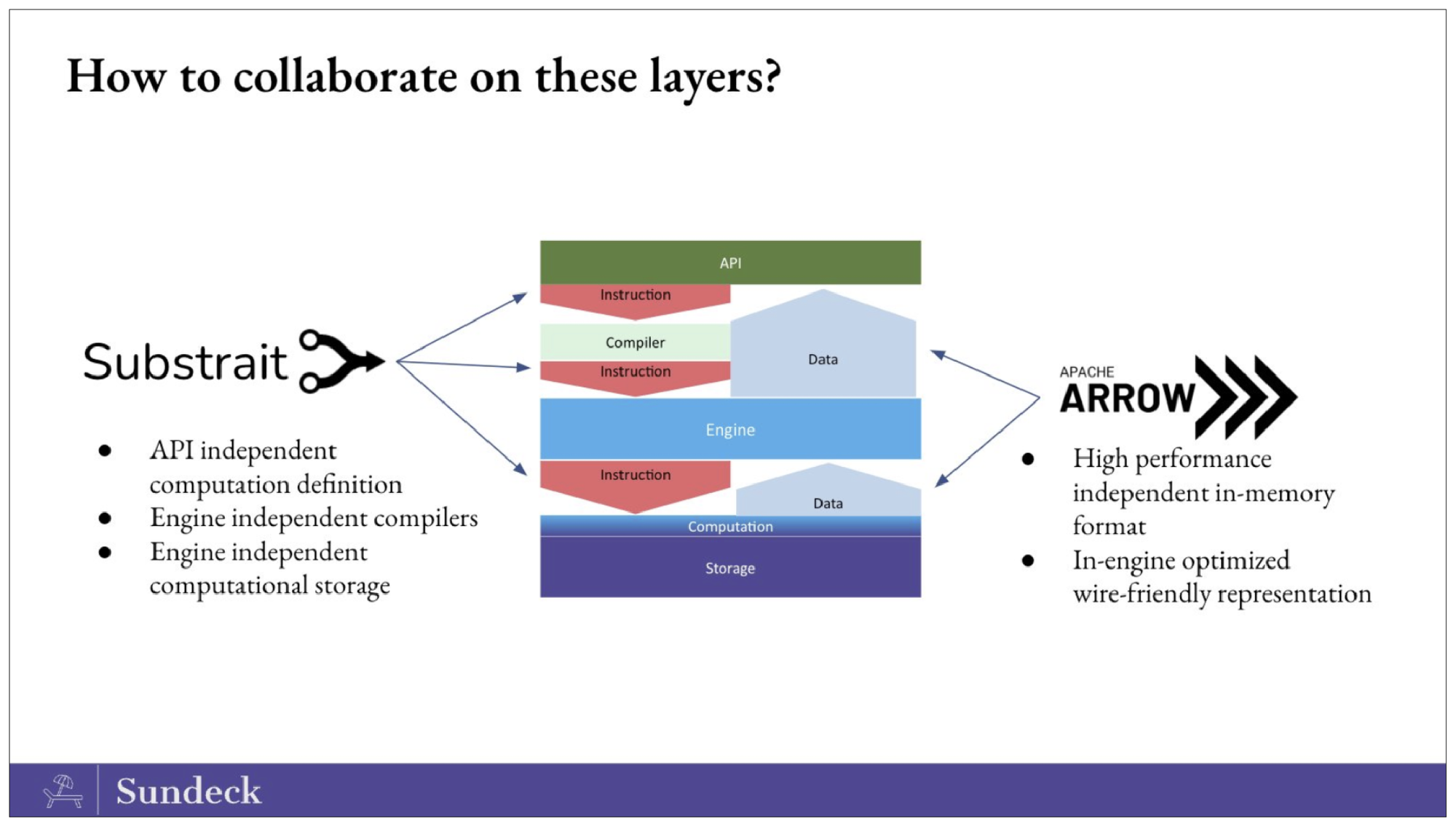
Substrait es una especificación interoperable y multilingüe para operaciones de cálculo de datos. Conecta las herramientas de análisis con los motores de computación, proporcionando una forma estándar y flexible para que todas estas capas del stack hablen un lenguaje común. Cuando se combina con Apache Arrow, un estándar universal para representar datos tabulares, los usuarios pueden conseguir un mayor rendimiento de una forma modular y componible.
El proyecto Substrait ha crecido enormemente en 2022. La especificación central -basada en Protocol Buffers- está bien establecida y puede representarse como binario o JSON. Se han creado enlaces y otras integraciones en ocho lenguajes: C++, C#, Go, Java, Python, R, Ruby y Rust. Se ha creado una estructura formal de gobernanza para garantizar que el proyecto pueda satisfacer las necesidades de un grupo diverso de partes interesadas.
8. LinceBI
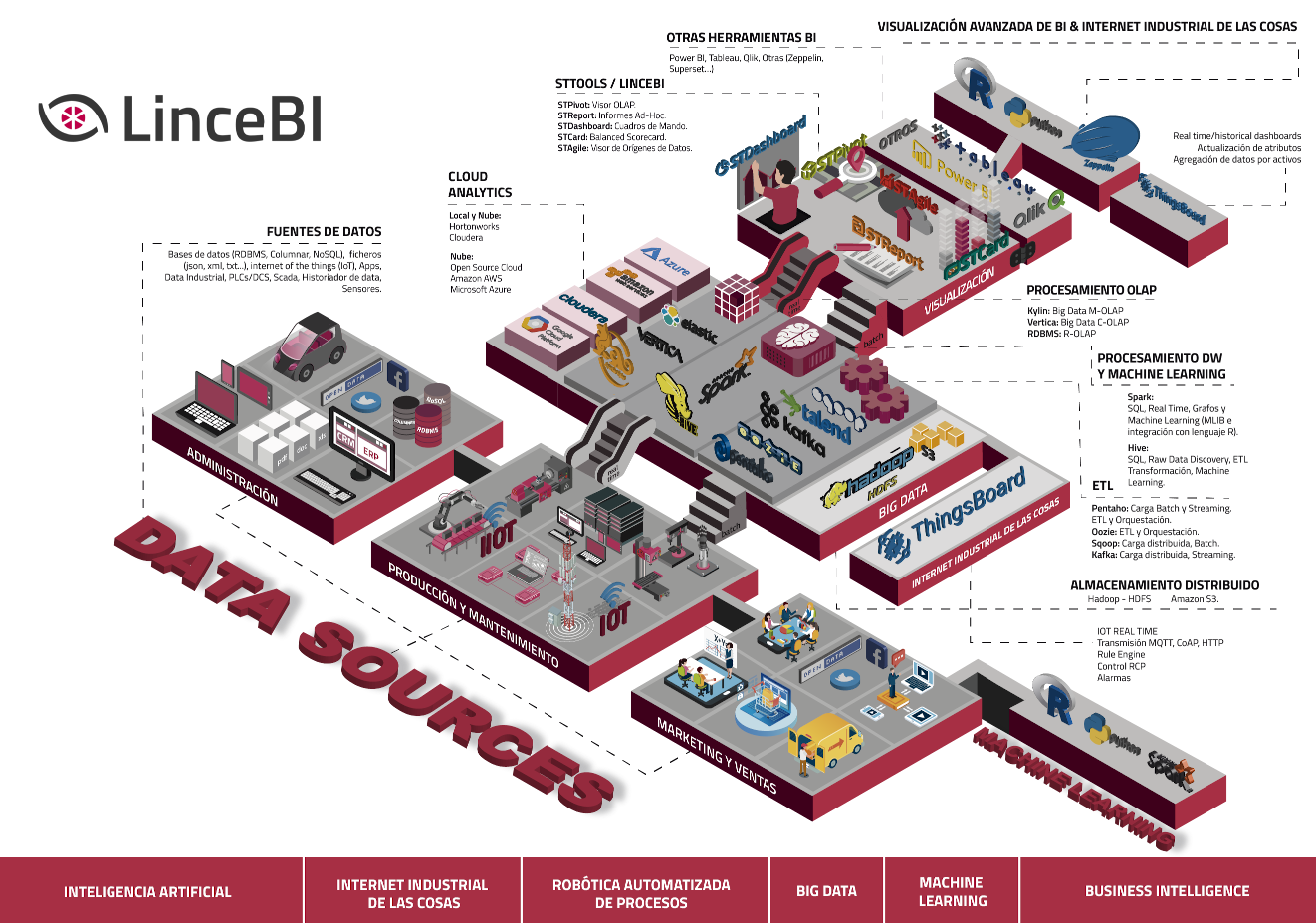
LinceBI es una aplicación de análisis que se integra con las principales herramientas open source del mercado del Business Intelligence y el Big Data, dotando a las empresas de la capacidad analítica que puedan necesitar
Actúa como un 'hub analytics', customizable y pudiendo funcionar tanto con sus propias herramientas como con las soluciones líderes y emergentes, tanto open source, como propietaria, como la reciente integración realizada con PowerBI
Está incluyendo funcionalidades de Augmented Analytics, como consultas en lenguaje natural, alertas inteligentes, etc...
LinceBI, que además es de origen español, se está consolidando como una de las mejores alternativas a las arquitecturas cerradas de datos, pudiendo adaptarse a las modernas arquitecturas, tanto en cloud como 0n-premise
9. Trino
Trino es un motor de consulta SQL distribuido de alto rendimiento para grandes datos. Su arquitectura permite a los usuarios consultar una variedad de fuentes de datos como Hadoop, AWS S3, Alluxio, MySQL, Cassandra, Kafka y MongoDB. Incluso se pueden consultar datos de múltiples fuentes de datos en una sola consulta. Trino es un software de código abierto impulsado por la comunidad y publicado bajo la licencia Apache.
Trino fue diseñado y desarrollado originalmente en Facebook para que sus analistas de datos ejecutaran consultas interactivas en su gran almacén de datos en Apache Hadoop. Antes de Trino, los analistas de datos de Facebook confiaban en Apache Hive para ejecutar análisis SQL en su almacén de datos de varios petabytes. Hive fue considerado demasiado lento
10. Apache Arrow
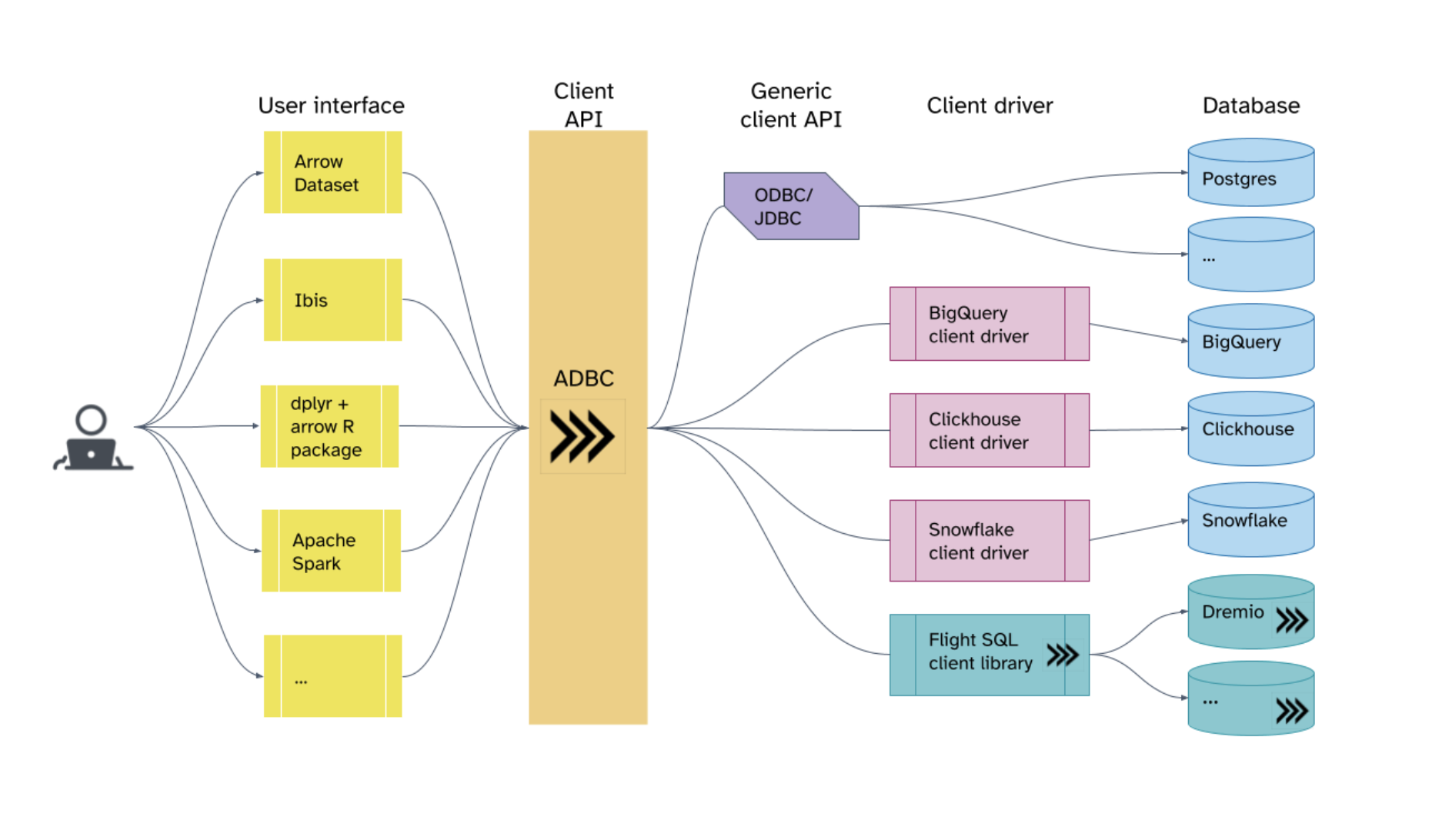
Apache Arrow es un marco de software independiente del lenguaje para desarrollar aplicaciones de análisis de datos que procesan datos en columnas.
El año pasado, Apache Arrow se descargó millones de veces -alcanzó los 70 millones de descargas en un mes-, lo que da fe de sus sólidas capacidades y su uso.
Apache Arrow Flight SQL se lanzó este año como un nuevo protocolo cliente-servidor para interactuar con bases de datos SQL. Utiliza el formato columnar en memoria Arrow y el marco Flight RPC. Al utilizar Arrow Flight SQL, una base de datos puede servir a usuarios ADBC, JDBC y ODBC desde un único punto final. Gracias a los controladores desarrollados por la comunidad de Arrow, tampoco es necesario escribir sus propios controladores.
En 2023, esperamos ver un mayor soporte de funciones en los controladores JDBC/ODBC y un mejor soporte de catálogos en el protocolo.
11. Polars
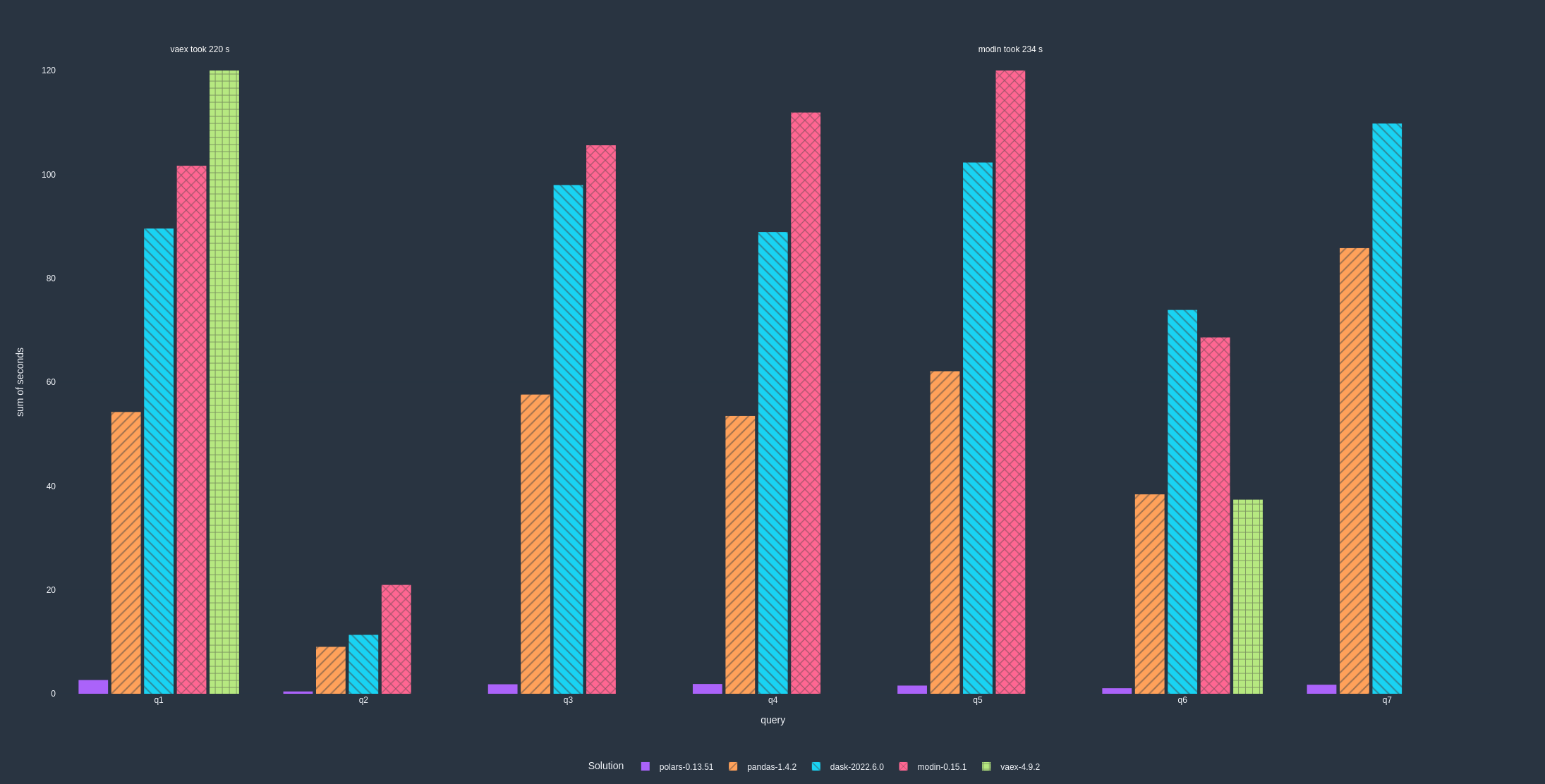
Polars está subiendo el listón de lo que se puede hacer y de la cantidad de datos que se pueden utilizar en el propio ordenador.
Ritchie Vink lanzó Polars como una rápida biblioteca de marcos de datos construida sobre Apache Arrow que utiliza todos los núcleos disponibles en las máquinas de los desarrolladores.
Escrita en Rust, Polars está diseñada para la paralelización de consultas sobre marcos de datos. La comunidad la está adoptando como alternativa a pandas porque resuelve muchos de los problemas de los desarrolladores de Python cuando se trata de limitaciones de memoria. Se trata de un motor de un solo nodo que ayuda a los desarrolladores a escalar ante conjuntos de datos masivos.
12. Redpanda
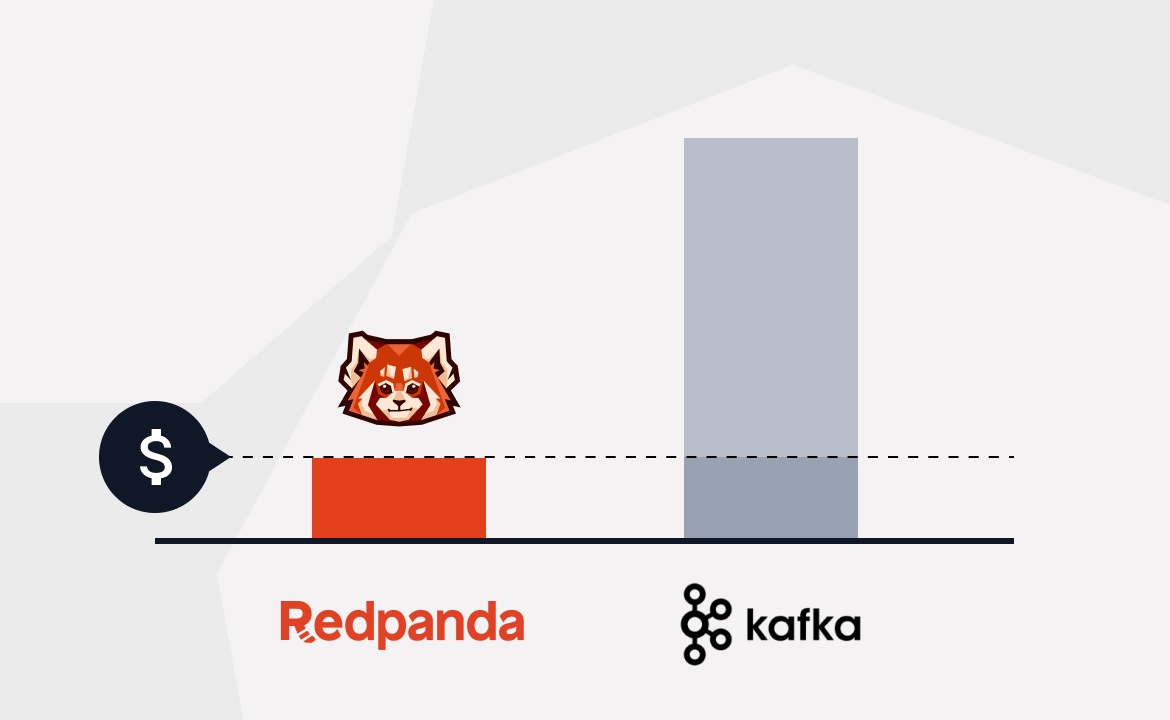
Redpanda es un proyecto de código abierto que se centra en el rendimiento y los estándares. Su misión es simplificar la complejidad de los sistemas de streaming de alto rendimiento, y lo están consiguiendo. Redpanda está eclipsando a Kafka como alternativa sencilla y rápida.
Redpanda está escrito en C++ utilizando un modelo de hilos por núcleo que maximiza la utilización del hardware moderno.
Están reconstruyendo Kafka utilizando primitivas vectorizadas de C++ para impulsar el rendimiento y subir la pila de forma útil. Redpanda es el motor de streaming subyacente para muchas aplicaciones y herramientas inteligentes.
Están alineados con el trabajo que Apache Arrow y Velox están realizando: es un trabajo de bajo nivel y alto impacto que pone el rendimiento, los estándares y la interoperabilidad en el centro.
13. HuggingFace
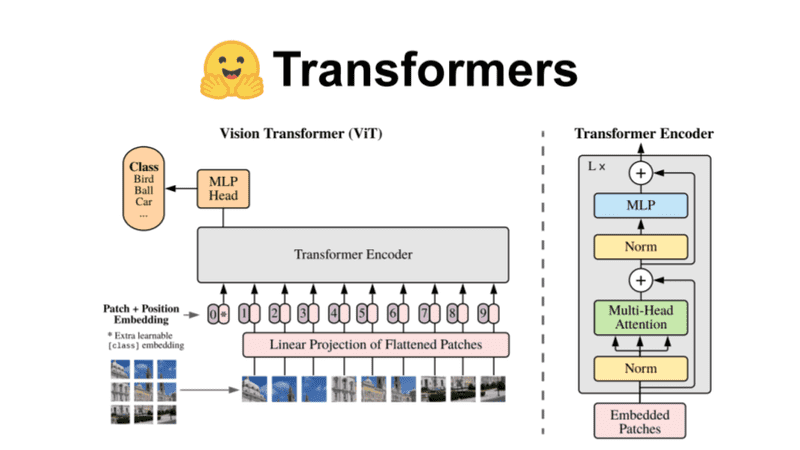
Hugging Face no es tan nuevo, pero sigue siendo un serio innovador en el espacio del aprendizaje automático (ML). En particular, la plataforma permite a los usuarios trabajar con conjuntos de datos Arrow y herramientas como NumPy, pandas, PyTorch y TensorFlow.
Sin embargo, Hugging Face es más que herramientas modernas. Es una vibrante comunidad de científicos de datos, investigadores e ingenieros de ML dedicados al avance de la IA. Aplaudimos que compartan sus conocimientos; su documentación es de grado A y tienen un canal de YouTube bien engrasado lleno de demostraciones y tutoriales.
14. Malloy
Malloy es un nuevo lenguaje de consulta para álgebra relacional que acaba de aparecer en escena de la mano de Google y está ganando interés en el ámbito del análisis de datos fuera de los principales lenguajes de programación.
Malloy es experimental y ofrece a los profesionales de los datos nuevas formas de componer datos anidados. Cada consulta que escribe un desarrollador es un bloque de construcción para desbloquear el siguiente nivel de comprensión, de modo que cuanto más se construye, más se entiende.
Malloy es el primer lenguaje de programación hiperdimensional construido para las necesidades de un mundo de big data.
¿Qué es la hiperdimensionalidad?
Cuando se trabaja con datos complejos y se desea ver las relaciones entre los datos, la hiperdimensionalidad permite la composición no sólo con medidas y dimensiones, sino con consultas enteras y a través del gráfico de relaciones. Esto expone todas las facetas interesantes de un conjunto de datos, simultáneamente, de forma fácil y comprensible.
- Malloy Project Page
- Malloy on GitHub
- Datanami article: "Looker Founder Helps Create New Data Exploration Language, Malloy"
15. Numba

Comparado con otros proyectos de código abierto de la lista, Numba es el "mayor" del grupo. Aún así, Numba sigue innovando.
Tiene todo el derecho a estar en esta lista. La interoperabilidad que Numba aporta al ecosistema es compatible con un conjunto muy amplio de casos de uso que siguen siendo relevantes y útiles.
Numba toma código Python y lo compila para ofrecerte la ventaja de velocidad de escribir en Python al tiempo que te da la velocidad de ejecución y el paralelismo de escribir en C. Es compatible con NumPy y CuPy y ofrece gestión de memoria que puedes utilizar para gestionar matrices de GPU y CPU.
Info en https://voltrondata.com/resources/12-open-source-projects-to-watch-2023