


A finales del mes pasado (Junio 22-26) tuvo lugar el evento anual de Databricks, la conocida distribución cloud del motor de procesamiento distribuido Big Data y machine learning open source, Apache Spark. En esta ocasión, las circunstancias impuestas por el Covid-19 han motivado que el evento se desarrolle íntegramente online y de forma gratuita.
En StrateBI hemos aprovechado la ocasión para que gran parte de nuestro equipo asista al evento, con el objetivo de conocer las novedades de Spark, Databricks y otras herramientas relacionadas que usamos a diario en nuestros proyectos Big Data y Machine Learning, con las que trabajamos habitualmente.
A continuación, la selección de charlas a las que asistió nuestro equipo:
Deep Dive into the New Features of Apache Spark 3.0
Una de las charlas más interesantes fue en la que los creadores de Spark comentaron las novedades de la nueva versión 3.0, la cuales se resumen en la siguiente imagen.

Las mejoras se han guiado en su mayoría por los 3.400 Jiras abiertos en proyecto de código open source. En primer lugar, destacan las mejoras en el rendimiento, evolucionando el optimizador de consulta (Catalyst) para la optimización adaptativa del plan de consulta en base los resultados de las etapas o tasks previas del job. Además, han mejorado la ejecución de consultas SQL con joins mediante tablas particionadas, logrando hasta un 33x sobre los típicos modelos de datos en estrella (tablas de hechos y dimensiones).
Por otro lado, destacan la incorporación de 32 nuevas funciones (built-in functions), las mejoras en la integración con los Dataframes de Pandas para la optimización de funciones UDF (Python) o el acelerador de la ejecución de los Jobs de Spark, el cual es capaz de hacer uso de otros recursos del clúster, como GPU’s, para mejorar la eficiencia en procesos de Deep Learning o procesamiento de señales. También destacamos las mejoras para la monitorización del streaming (Structured Streaming UI), la disponibilidad de nuevas métricas y alertas para medir la calidad de los procesos streaming, las nuevas funcionalidades para optimizar la lectura de fuentes de datos Parquet y CSV y el completo soporte para Hadoop 3.X, Java 11 y Apache Hive 3, al mismo tiempo que sigue manteniendo la compatibilidad sus versiones anteriores.
Delta Lake, Spark on Kubernetes, Presto y resto de charlas
Además de las interesantes novedades de Spark 3.0, otra de las charlas más interesantes fue la relacionada con los frameworks para el soporte de transacciones ACID en Spark, es esto, la gestión eficiente de las actualizaciones de datos y esquema de las tablas o archivos de nuestro Data Lake.
La ya conocida propuesta de Databricks es Delta Lake, basada en el formato Parquet y también disponible en Spark, pero han surgido otras dos opciones a tener en cuenta: Apache Iceberg y Apache Hudi. En la siguiente captura podemos ver la comparación entre las 3 alternativas:
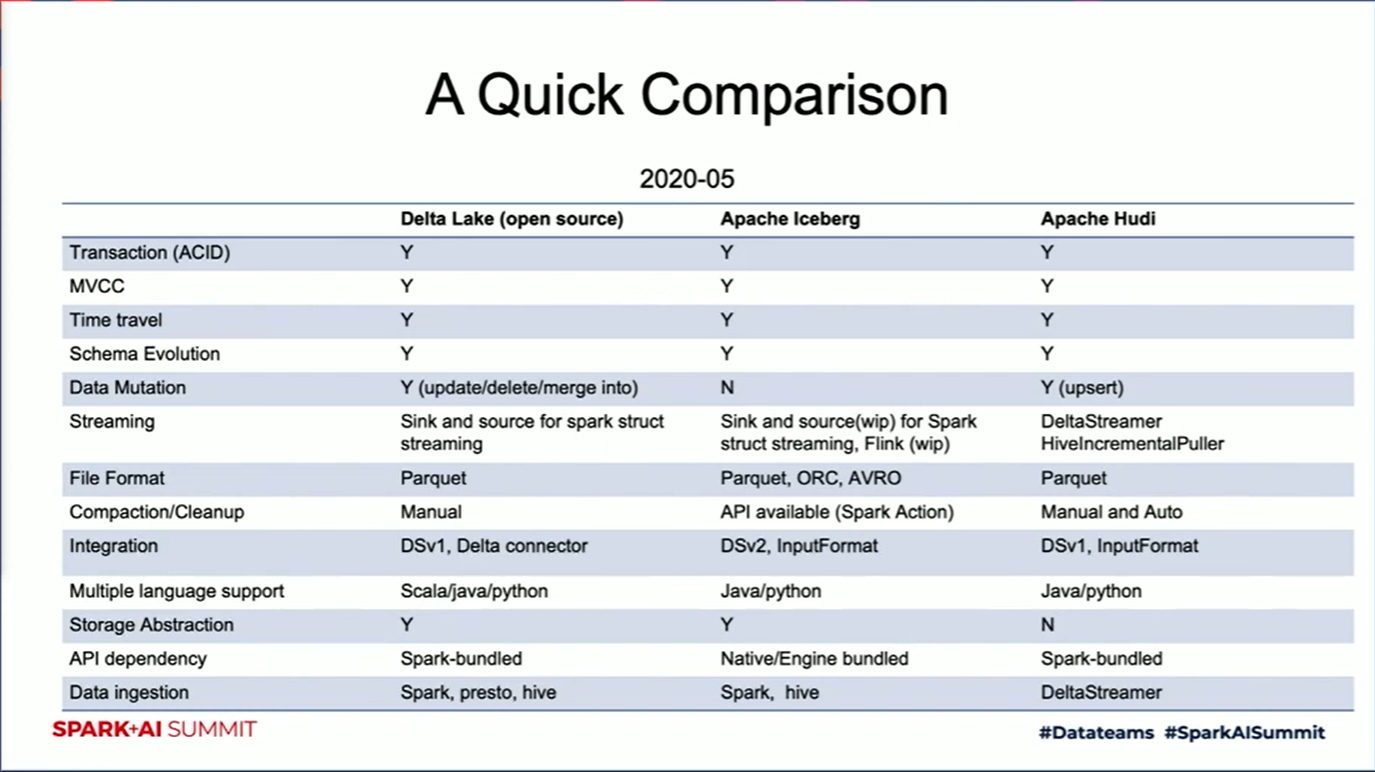
Una de las características claves es el soporte para la mutación de datos. En el caso de Delta Lake soporta tanto actualizaciones como borrados: merge, update y delete para permitir casos de uso complejos como la captura de datos cambiantes (change-data-capture), slowly-changing-dimensions (SCD) u upserts sobre flujos de streaming.
Sin embargo, en el caso de Hudi, el soporte queda reducido a las actualizaciones (upserts) y en el caso de Iceberg, no se soporta actualización de datos. Sin duda Delta Lake es la herramientas más madura, pero Huidi e Iceberg potencian otras características cuya evolución tendremos que seguir de cerca en los próximos meses.
Otra de las charlas que despertó nuestro interés, fue la relacionada con la ejecución de Apache Spark en un clúster de Kubernetes (K8s). En esta sesión los fundadores de Data Mechanics, nos contaron su experiencia en la creación y puesta en producción de una plataforma Big Data serverless de Spark sobre Kubernetes. Muy interesante fue la comparación realizada entre la forma tradicional de usar Spark con el gestor de recursos YARN, frente a la solución usando Kubernetes, que cuenta con su propio gestor especifico para este tipo de despliegue.
Una de las principales ventajas que destacan en K8s es que cada aplicación de Spark se ejecuta en su propio contenedor aislado de Docker, mientras que con YARN se necesita una versión global de Spark, Python y resto de dependencias, por lo que en YARN existe una falta importante de aislamiento. Sin embargo, identifican como desventajas de Spark en Kubernetes la alta curva de aprendizaje para su despliegue, un complejo mantenimiento del clúster o la falta de madurez, pues hasta hace poco era una característica experimental.
Por otro lado, también nos resultó muy interesante la charla sobre la herramienta Apache Presto, en su versión cloud y Enterprise Starburst. Aunque Spark es una herramienta que soporta consultas SQL de forma eficiente, además de muchos otros tipos de procesamiento de tipo ETL o Machine Learning, Apache Presto potencia la ejecución interactiva de consultas SQL sobre Big Data al mismo tiempo que soporta una concurrencia de usuarios muy alta. Esta herramienta puede ser considerada como una herramienta de tipo Big Data OLAP, tipología a la cual pertenecen otras herramientas como Apache Kylin(Kyligence) o Apache Druid. Estas herramientas pueden usarse como complemento de Spark/Databricks en una arquitectura Big Data, para cubrir todas las necesidades de procesamiento y analíticas que puedan surgir.
Entre las ventajas más interesantes que propone Presto, destaca la posibilidad de hacer consultas SQL directamente (sin copiar datos) sobre múltiples orígenes de datos (ej. Hive, Elasticsearch, PostgreSQL, Kafka, …) y combinando los mismos en un única consulta SQL (Federated Queries). Incluso han creado un conector con Delta Lake, el cual hace uso de algunas de las optimizaciones más importantes de este formato para conseguir un incremento en el rendimiento de consulta frente a otros orígenes de datos. En StrateBI estamos impacientes por comprobar su rendimiento frente alternativas como Apache Kylin, sobre el cual ya hemos comprobado su eficacia con el benchmark TPC-H en nuestro estudio.
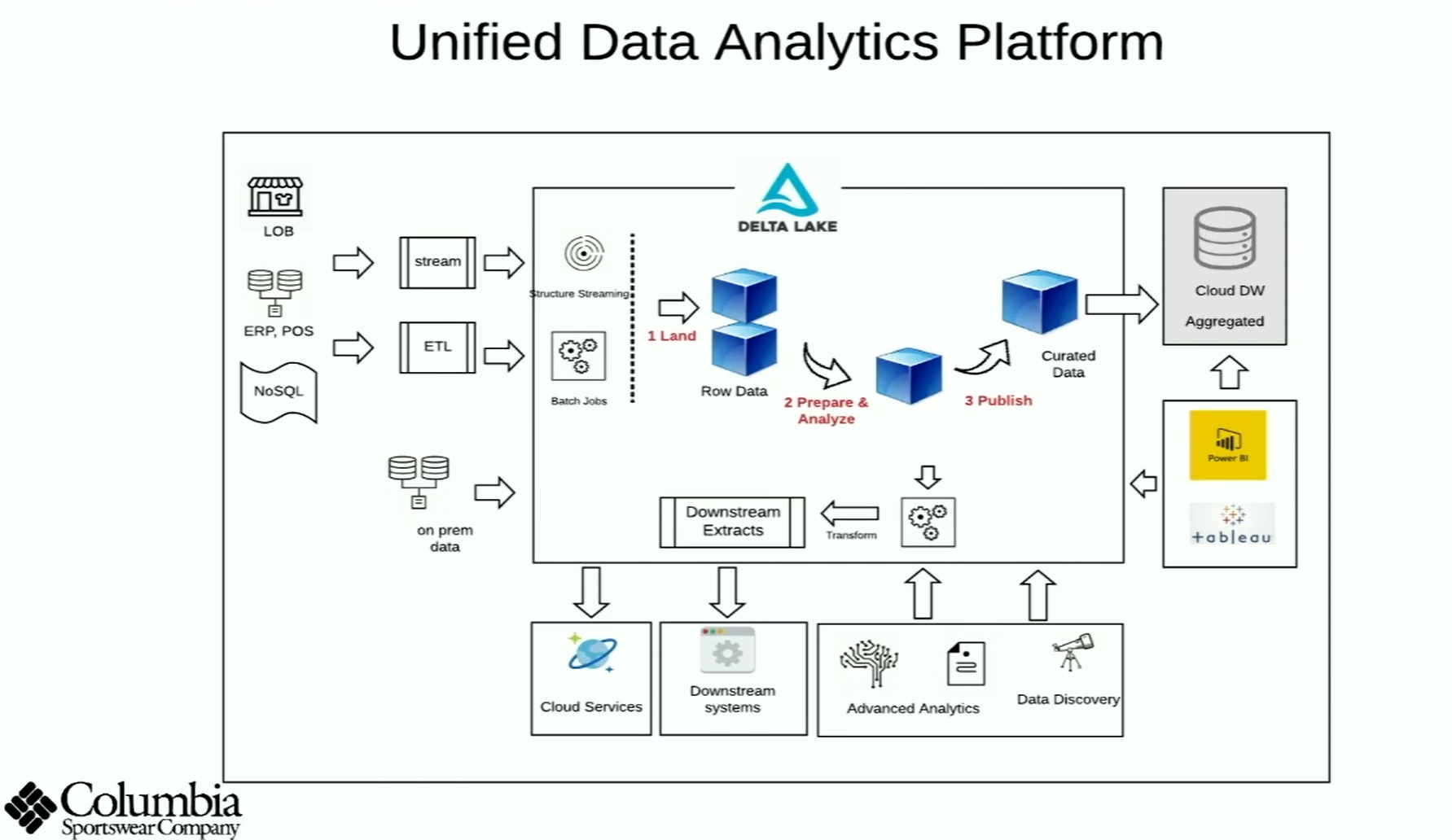
También destaca la ponencia de la empresa de ropa deportiva Columbia, sobre su experiencia en la migración de una arquitectura de Data Warehousing tradicional a una plataforma Big Data cloud basada en Azure. Para la evolución de su sistema, escogieron una arquitectura basada principalmente en Azure Databricks (usando Delta Lake), Data Factory y Synapse (antes conocido como SQL DW).
Azure Synapsepermite el almacenamiento y la explotación eficientes de datos mediante la integración con Databricks, consultas SQL o desde informes de Power BI y Tableau. Recientemente hemos implantado en Stratebi en dos de nuestros clientes más relevantes una arquitectura que incluye estas herramientas, por lo que podemos confirmar que se trata de una arquitectura que garantiza el éxito en el procesamiento de Big Data, especialmente en la evolución de sistemas de BI tradicionales hacía escenarios Big Data.
Por último, hay que destacar la charla dónde se trató la integración con Databricks con la herramienta Talend Studio BigData Plataform, de la que somos Partners, para el diseño de procesos de transformación de datos de forma visual (sin escribir código) que se pueden ejecutar de forma transparente para el usuario en Spark o Databricks, aprovechando de esta forma las ventajas de la ejecución distribuida al mismo tiempo que se reduce la curva de aprendizaje de Spark.
