

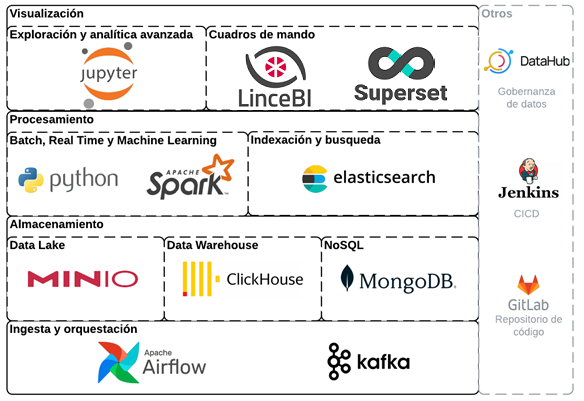
Cuando queremos definir la Arquitectura tecnológica de un Data Lake, éste debe permitir la ingesta, integración, almacenamiento y explotación de cualquier tipo de fuentes de datos
Apostamos por el uso de software libre, pero para el que exista un importante soporte de la comunidad de usuarios que facilite su uso y garantice la continuidad de la herramienta a largo plazo. Nuestro compañero, Roberto Tardío de Stratebi, nos lo cuenta
Teniendo en cuenta los requisitos anteriores, os proponemos un arquitectura open source que cubre todas las necesidades de un Data Lake actual,
Almacenamiento
El flujo de datos natural a través de esta arquitectura puede seguirse desde la parte inferior de la imagen, comenzando con las herramientas para la ingesta de datos.
En este sentido apostamos por Apache Kafka para la ingesta de datos en tiempo real, implementando esta herramienta una cola de mensajes distribuida que actúa como buffer en procesos real time. Mientras que para la ingesta batch apostamos por la herramienta Apache Airflow, combinada con otras herramientas de la arquitectura como Apache Spark o Clickhouse. Apache Airflow actúa como una herramienta de orquestación que nos permite invocar a otros procesos creados con el resto de las herramientas propuestas, componiendo de esta forma flujos de datos que pueden ser invocados de manera recurrente para la ejecución de cargas, con la a frecuencia requerida por el proceso implementado (ej. horaria, diaria, semanal,…).
En cuanto al almacenamiento de los datos ingestados desde las fuentes, proponemos distintas alternativas en función del tipo de fuente de datos (ej. estructurados, semi o no estructurados) o el caso de uso (ej. cuadros de mando, ciencia de datos, indexación y búsqueda en documentos).
En primer lugar, para la implementación de un Data Lake que permita almacenar cualquier tipo proponemos la herramienta MinIO. Se trata de un almacenamiento de objetos que se instala distribuido en un clúster de máquinas, por lo tanto, altamente escalable.
Al mismo tiempo tiene unas altísimas prestaciones de lectura/escritura que hacen idónea esta herramienta para el procesamiento del Big Data. A esto se añade la compatibilidad con la interface o API de S3, desarrollado por Amazon AWS y usado para la comunicación con su almacenamiento en la nube. Esto significa que MinIO como almacenamiento on premise, es compatible todas las herramientas que soportan el estándar S3, incluyendo todas las herramientas propuestas en esta arquitectura y la mayoría de otras aplicaciones Big Data existentes en la actualidad. Esto es una fuerte garantía para la interoperabilidad de la arquitectura propuesta.
En segundo lugar, como destino de la información ingestada o procesada con otras herramientas como Kafka o Spark, proponemos la implementación de un Data Warehouse mediante la herramienta ClickHouse. Este sistema distribuido permite la implementación de bases de datos estructurados mediante esquemas de tablas relacionales, con altísimos rendimiento en la lectura y escritura de datos con grandes volumenes de datos, soporte para actualización de filas, seguridad e integración con S3 (MinIO), Kafka, Spark,…
Es importante resaltar que la estructuración de datos y su almacenamiento en un Data Warehouse es fundamental para creación de cuadros de mando sobre información consolidada con otras herramientas de la arquitectura como Apache Superset o LinceBI
Como tercer sistema de almacenamiento, proponemos el sistema de base datos distribuido NoSQL documental MongoDB. Este sistema es bastante útil para el almacenamiento y consulta de datos semi estructurados que provienen origenes como sensores, transacciones de cualquier sistema u otros de tipo web (ej. datos abiertos) que en muchas ocasiones se proporcionan en formatos semi estructurados como JSON. A diferencia del Data Warehouse (click house) cuyo objetivo principal es el soporte al análisis de datos, el objetivo principal de MongoDB será almacenar datos semi estructurados para hacer consultas al detalle sobre los mismos y como repositorio fuente para otras herramientas de nuestra arquitectura, como Apache Spark.
Procesamiento
Por otro lado, para la indexación y búsqueda de datos en documentos, proponemos usar Elasticsearch. Esta herramienta podría ser considerada con un cuarto sistema de almacenamiento, en este caso enfocado a procesos de análisis de datos de tipo real time cuyo tiempo de preproceso tiene que ser muy rápido. Como herramienta de explotación de los datos almacenados y indizados en Elasticsearch se propone el uso de la herramienta Kibana, la cual forma parte de la misma suite de herramientas Elastic.
En cuanto a la transformación de datos, tanto para procesos batch como real time, así como para los procesos de ciencia de datos, proponemos el uso de Apache Spark. Esta herramienta se ejecuta de forma distribuida en un clúster de máquina y soporta prácticamente todos los formatos de fuentes y complejidad de estructura de datos, soportando cualquier escenario Big Data requerido. Para desarrollar en Apache Spark, proponemos el uso del lenguaje Python, combinando con el uso de Dataframes y lenguaje SQL. No obstante, esta herramienta soporta otros lenguajes como Scala, Java o R. La ejecución de los procesos de Spark se orquestará con Apache Airflow y permitirá implementar entre otros los siguientes tipos de procesos, tanto de tipo batch como en real time:
- Limpieza, estructuración, consolidación y combinación de los datos almacenados en MinIO, MongoDB, ClickHouse, Elasticsearch o recibidos a través de Kafka en tiempo real.
- Lectura y escritura en cualquiera desde o hacia cualquiera de los almacenamientos propuestos: MinIO, MongoDB, ClickHouse, Elasticsearch y Kafka.
- Implementación de procesos de ciencia de datos:
Clasificación: regresión logística, naive Bayes, ...
Regresión: generalized linear regression, survival regression, ...
Árboles de decisión, bosques aleatorios y árboles con refuerzo de gradiente
Recomendación: mínimos cuadrados alternos (ALS)
Agrupación: K-means, mezclas gaussianas (GMM), ...
Topic modeling: asignación de Dirichlet latente (LDA)
Conjuntos de elementos frecuentes, reglas de asociación y minería de patrones secuenciales
- Otros...
- Transformaciones de características: estandarización, normalización, hashing,...
- Construcción de pipelines de ML
- Evaluación de modelos y ajuste de hiperparámetros
- Persistencia de ML: guardar y cargar modelos y Pipelines
- Álgebra lineal distribuida: SVD, PCA,...
- Estadísticas: estadísticas de resumen, pruebas de hipótesis,...
Visualización
Adicionalmente, para el desarrollo, visualización y compartición de procesos de analítica avanzada se propone el uso de la herramienta de notebooks Apache Jupyter. Esta herramienta permite crear cuadernos donde se puede escribir y ejecutar código Python (con o sin Spark), Scala, SQL (ej. sobre el Data Warehouse Clickhouse) o R, permitiendo además mostrar visualizaciones sobre los datos y compartir estos notebooks con otros usuarios de la organización (ej. científicos) que pueden trabajar de forma simultanea en el desarrollo o simplemente leer y analizar los resultados mostrados visualmente.
De esta forma, consideramos que Jupyter es una herramienta idónea para que los equipos de la organización, para explorar con detalle datos previamente datos procesos o desarrollar nuevos casos de estudio de ciencia de datos.
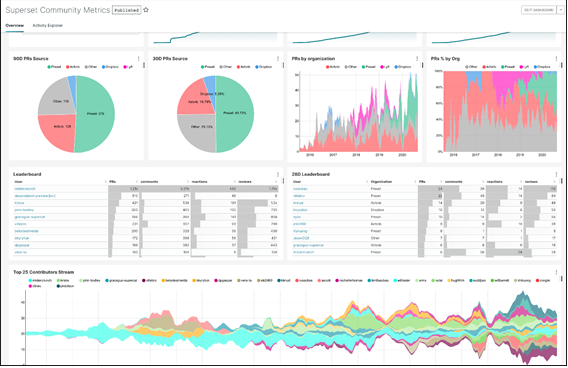
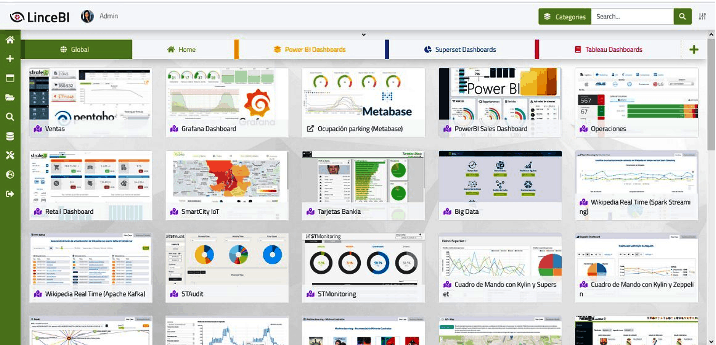
Por otro lado, para la creación de cuadro de mando sobre datos consolidados almacenados en el Data Warehouse (Clickhouse) se propone el uso de Apache Superset y LinceBI, una herramienta open source que permite el desarrollo de cuadros de mando de forma muy ágil, mediante el uso de un gran número de componentes gráficos pre-creados y consultas SQL a la base de datos origen. Los componentes se arrastran a un lienzo para componente el cuadro de mando, que puede ser compartido con la seguridad necesaria con otros usuarios o grupos de usuarios, dentro y fuera de la organización
Gobierno del Dato
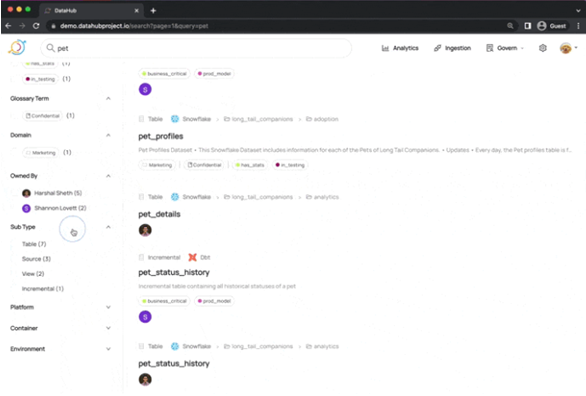
Otra de las herramientas fundamentales en nuestra arquitectura es la herramienta open-source Linkedin DataHub, la cual nos va a permitir implementar la estrategia de Gobierno del Dato que diseñaremos en las primeras etapas del proyecto. Esta herramienta soporta un moderno catálogo de datos con una atractiva interfaz web visual para permitir el descubrimiento de datos de principio a fin, la observación de la evolución o transformación de los datos y la gobernanza de estos en nuestra organización. Es una plataforma de metadatos extensible creada para que los desarrolladores puedan controlar la complejidad de sus ecosistemas Big Data en rápida evolución y para que los profesionales de los datos (ej. científicos, analistas, ejecutivos, …) puedan aprovechar el valor total de los datos dentro de su organización.
Esta herramienta incluye integración con todas las herramientas de almacenamiento y procesamiento de la arquitectura propuesta (Kafka, S3 (MinIO), Clickhouse, MongoDB, Elastic Search, Spark y Airflow), así como con muchas otras herramientas Big Data. Entre sus características destacan:
- Búsqueda y descubrimiento: en todas las herramientas de almacenamiento de la arquitectura propuesta.
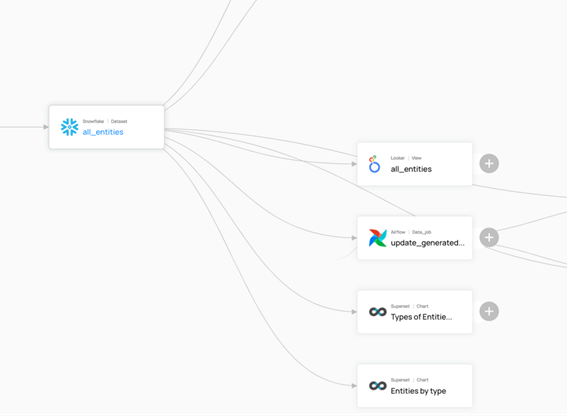
- Linaje de los procesos de datos (ETL/ELT) implementados con AirFlow, Kafka, Spark,… y visualización con Superset, permitiendo entender estos procesos de principio a fin y como los cambios en los conjuntos de datos pueden afectar a estos.
- Combinación de metadatos de negocio o lógicos con metadatos técnicos para soportar una visión 360 de los datos de todas las entidades almacenadas.
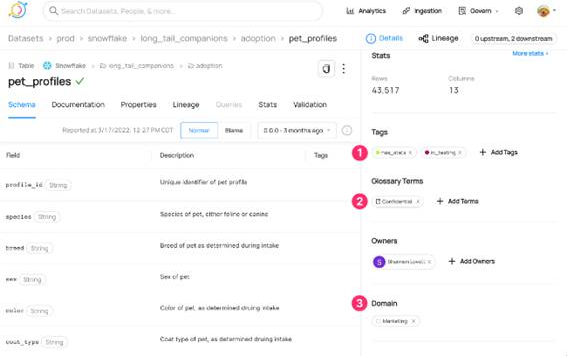
- Gestión de los propietarios o responsables de los datos. Permitir a estos usuarios gobernar usando elementos como: Etiquetas informales para mejora búsqueda y descubrimiento, glosario de términos y dominios, para organizar las entidades por departamento (por ejemplo, Finanzas, Marketing) o productos de datos.
- Crear usuarios, grupos y políticas de acceso: Definir quién puede realizar qué acción contra qué recurso(s).
- Configuración de la ingesta de metadatos para los distintos almacenamiento y esquemas desde la interfaz de usuario, permitiendo programar de forma recurrente la actualización de los metadatos.
- Notificaciones en tiempo real.
Por último, para la gestión del código desarrollado para los distintos tipos de procesos se hará uso de un servidor on-premise de GitLab. Por otro lado, para el despliegue automatizado de las distintas herramientas propuestas en las máquinas aprovisionadas, así como para la integración y despliegue del código desarrollado en los distintos entorno (desarrollo, pre producción y producción) se hará uso de la herramienta Jenkins
Es importante resaltar que las herramientas de la arquitectura propuesta pueden ir incorporándose a esta arquitectura de forma incremental, a medida que se vayan necesitando en los casos de uso que se identifiquen por la organización o con relación a otros requisitos, como la disponibilidad de las máquinas hardware necesarias. En cualquier caso, esta propuesta de arquitectura se revisará en la etapa de análisis y diseño al inicio del proyecto para la generación de una versión final en base a el análisis en detalle de los requisitos que se llevará a cabo una vez iniciado en el proyecto