


1. Introducción
GraphQL es un lenguaje desarrollado por Facebook para realizar consultas contra una API que expone unos datos. Para establecer un contexto, al hacer uso de APIs Rest, no contamos con flexibilidad a la hora de solicitar datos.
Las consultas están prediseñadas y nos limitamos a especificar determinados parámetros de acuerdo con el diseño de la API. Este funcionamiento, muchas veces, resulta en tener que realizar varias consultas encadenadas para obtener justo la información que necesitamos o nos encontramos con que la API nos devuelve muchos datos que nos sobran y, por tanto, tenemos que realizar un filtrado en el cliente para extraer únicamente los datos buscados.
De estas limitaciones nace la motivación de GraphQL, pues nos aporta la libertad de la que carece el paradigma Rest.
GraphQL permite realizar consultas personalizadas al definir de forma específica los campos que esperamos recibir como respuesta. De este modo, en lugar de preguntar, por ejemplo, por un usuario y recibir todos sus campos (id, nombre, apellidos, etc.), si lo que nos interesa es únicamente su nombre, podemos limitar la consulta a ese dato.
Este paradigma aporta una enorme flexibilidad a la hora de utilizar una única API para que clientes con propósitos distintos puedan consultar los datos que requieren de una forma eficiente. Esto no implica necesariamente que GraphQL sea un reemplazo para el paradigma Rest.
A lo largo del documento se va a ejemplificar el uso de GraphQL en torno a una API que permite consultar y modificar información correspondiente a productos, que podría ser muy útil, por ejemplo, en el contexto de una web de comercio online.
Referencias:
Página principal web: https://graphql.org/
Documentación oficial de aprendizaje: https://graphql.org/learn/
Acceso a la herramienta:
GraphQL tiene soporte para muchos de los lenguajes más usados actualmente. En este documento nos centramos en Python, pero en este enlace se puede consultar la instalación para cada uno de los lenguajes disponibles.
En este ejemplo vamos a optar por la implementación ariadne. La instalación es muy simple (prerrequisito contar con una instalación de Python y pip):
- En primer lugar, ejecutar en una terminal: pip install ariadne
- Para importar en un script: import ariadne
2. Realización de consultas con graphQL
Las consultas en GraphQL se estructuran de forma similar a un texto JSON donde especificamos los datos que esperamos recibir. De este modo, el servidor toma la consulta como una plantilla donde “rellenar” los datos correspondientes. Es por esto que es tan sencillo limitar y filtrar los datos dentro de la propia consulta, de forma parecida a como haríamos en SQL directamente contra la base de datos.
Obtención de un listado de un recurso concreto:
En este primer ejemplo vamos a solicitar el listado del recurso con todos sus campos.
Consulta:
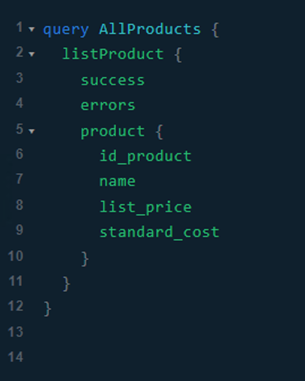
Respuesta:
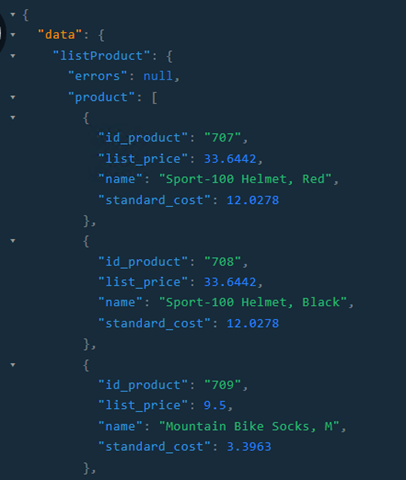
Ahora pedimos el listado, pero descartamos los campos success (que no llega a visualizarse en el resultado anterior por encontrarse al final del listado) y errors. Del producto solicitamos únicamente el nombre y el precio.
Consulta:
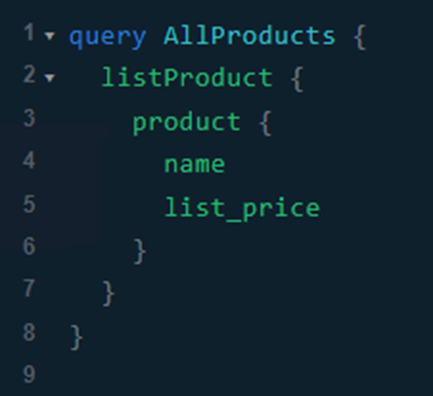
Respuesta:

Obtención de un único elemento utilizando su id como parámetro:
En este caso vamos a consultar un producto en concreto a partir de su identificador.
Consulta:
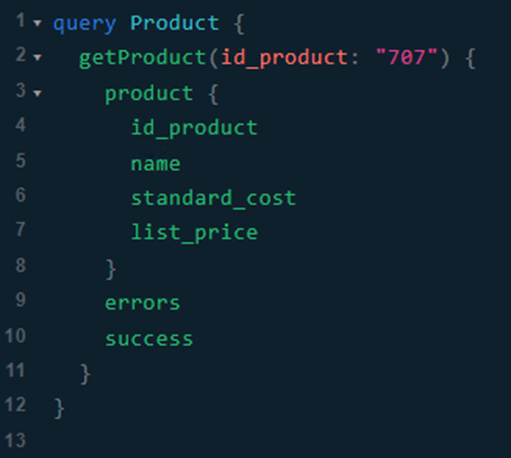
Respuesta:
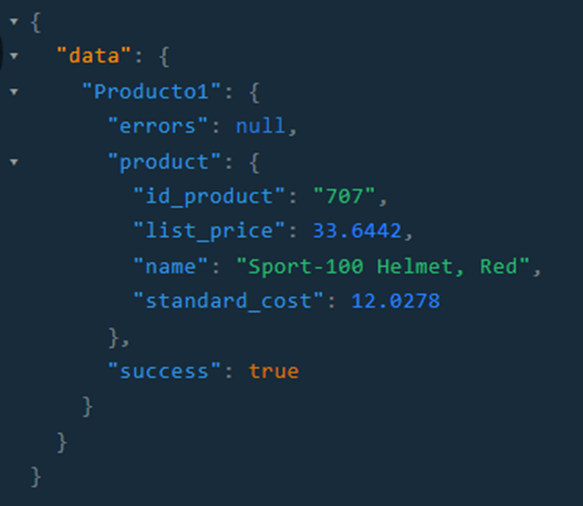
Por último, para mostrar algunas posibilidades más de las consultas de GraphQL, realizamos otra consulta similar a la anterior, pero esta vez seleccionamos dos productos distintos en la misma consulta. Para ello se incorpora el concepto de alias que permite asignar un nombre que elijamos a cada resultado obtenido. Además, podemos seleccionar campos distintos para cada producto.
Consulta:
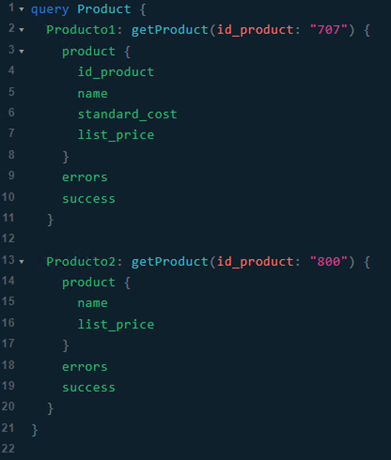
Respuesta:
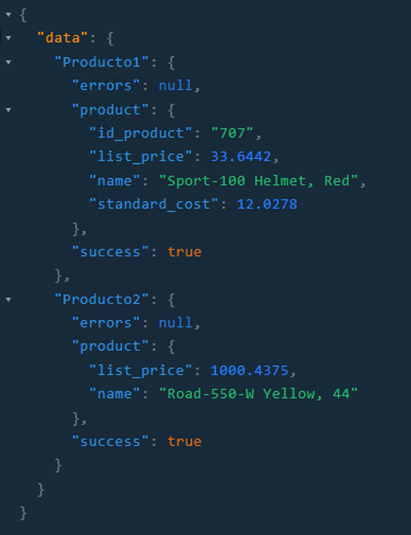
3. Mutaciones
En el contexto de GraphQL, a todas las operaciones que implican una modificación de los datos se les denomina mutaciones. Esto engloba a las operaciones de creación, actualización y borrado. Se efectúan de una forma muy similar a las consultas, haciendo uso de parámetros.
Adición de nuevos datos:
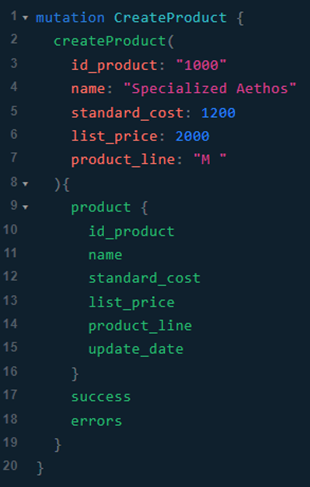
· Normalmente no debe establecerse el id en el cliente al crear un recurso. Es así en este ejemplo por las características de la base de datos sobre la que estamos operando.
Respuesta del servidor con el recurso creado (por haberlo solicitado a continuación de los parámetros en la consulta):
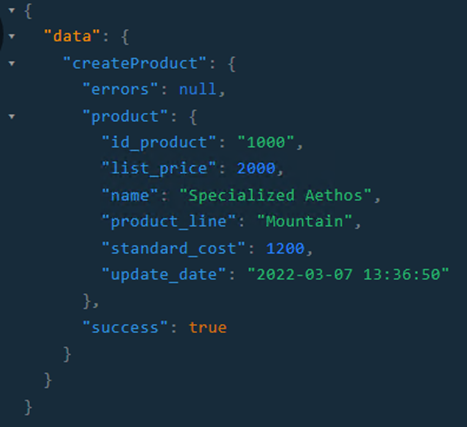
Modificación de datos:
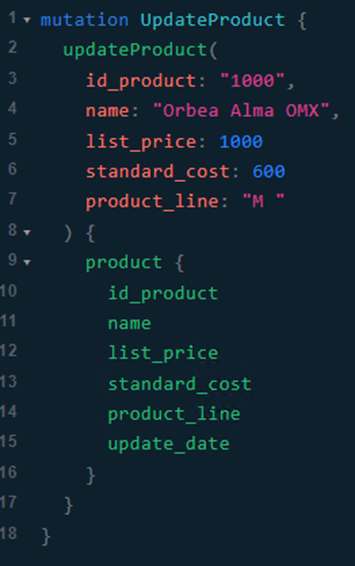
Respuesta del servidor, al igual que en el ejemplo anterior, pidiendo que se nos muestre el recurso modificado:
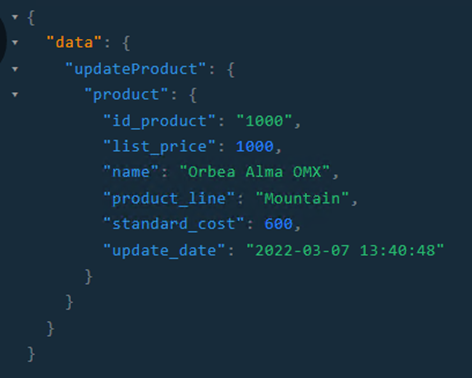
Por último, el borrado de datos:
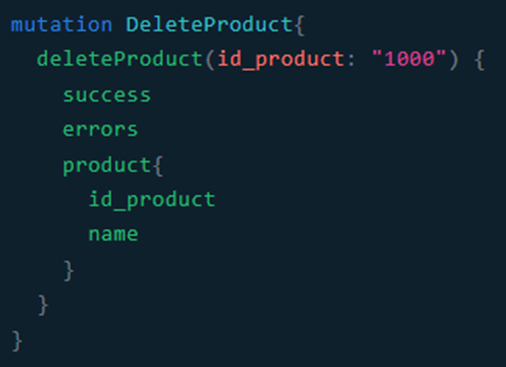
Y la consiguiente respuesta del servidor, pidiéndole también que nos muestre el recurso eliminado con dos de sus campos:

4. Schema de GraphQL – modelado de los datos
El concepto de schema en GraphQL es similar a la idea de schema en XML o JSON para quien esté familiarizado con ello. Es una forma de modelar los datos que debe manejar la API definiendo su estructura. Es por esta razón que podemos realizar las consultas mostradas anteriormente: existe un schema detrás que da esa forma a los datos y dice al servidor qué información corresponde a cada campo.
El schema en GraphQL debe definir:
- Los recursos a los que se puede acceder mediante la API. En el caso anterior, el recurso producto. Aquí se definen los campos que lleva asociados el recurso (id, nombre, precio, etc.)
- El formato de la respuesta para cada una de las posibles consultas. En el caso anterior se define una respuesta para solicitar la lista de productos y otra para solicitar el producto único. Es equivalente a definir el formato de la consulta que se quiere realizarcon los campos que deben ser devueltos por el servidor (errors, success y producto en el ejemplo).
- Una definición de todas las consultas y mutaciones que expone la API, indicando los parámetros si se requieren (el id en el ejemplo de la consulta de un producto único) y el tipo de dato que debe ser devuelto, es decir, qué respuesta de las definidas en el paso antes mencionado se corresponde con cada consulta.
Se pueden observar además dos modificadores de campo:
- !: La exclamación especifica que el campo no puede ser nulo
- []: Los corchetes indican que se va a proporcionar un listado.
Para aclarar el concepto, se muestra el schema correspondiente con el ejemplo anterior.
schema {
query: Query
mutation: Mutation
}
type Product {
id_product: ID!
name: String!
standard_cost: Float
list_price: Float
}
type ProductResult {
success: Boolean!
errors: [String]
product: Product
}
type ProductListResult {
success: Boolean!
errors: [String]
product: [Product]
}
type Query {
getProduct(id_product: ID!): ProductResult!
listProduct: ProductListResult!
}
type Mutation {
createProduct(id_product: ID!, name: String!, standard_cost: Float!, list_price: Float!, product_line: String!, update_date: String): ProductResult!
updateProduct(id_product: ID!, name: String, standard_cost: Float, list_price: Float, product_line: String, update_date: String): ProductResult!
deleteProduct(id_product: ID): ProductResult!
}
5. Implementación de una api con GraphQL
A continuación, se muestra un ejemplo de implementación de una API muy simple que permite leer datos de una base de datos MySQL haciendo uso de GraphQL. Como se comentaba en la introducción, para contextualizar el caso de uso, podríamos encontrarnos ante el desarrollo de una API para una aplicación de comercio online, donde visualizar la información de los productos en una aplicación móvil o web.
Para poder visualizar el ejemplo de forma más completa, el código se puede encontrar en:
https://github.com/Stratebi/api_graphql
Base de la aplicación:
Para el desarrollo del ejemplo y poder probar las consultas, se hace uso del framework Flask para Python. Todo el código del ejemplo está escrito en este lenguaje haciendo uso de la librería Ariadnepara GraphQL.
La API conecta con una base de datos MySQL que contiene un Data Warehouse con información correspondiente a una serie de productos y el estado de inventario. Para esta conexión, se usa SQLAlchemy, integrado en Flask.
En un fichero __init__.py se define la URL de conexión a la base de datos y se inicializa la aplicación Flask junto con los parámetros necesarios para la conexión a la base de datos.
from flask import Flask
from flask_cors import CORS
from flask_sqlalchemy import SQLAlchemy
from api.secrets import DbSecrets
credentials = DbSecrets()
conn = "mysql+pymysql://{0}:{1}@{2}/{3}".format(credentials.dbuser, credentials.dbpass, credentials.dbhost, credentials.dbname)
app = Flask(__name__)
CORS(app)
app.config['SQLALCHEMY_DATABASE_URI'] = conn
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
db = SQLAlchemy(app)
En este caso, para facilitar la parametrización, se han externalizado los parámetros de conexión de la URL a un fichero aparte llamado secrets.py de la forma siguiente:
class DbSecrets:
def __init__(self):
self.dbhost = 'dirección del host que alberga la base de datos'
self.dbuser = 'usuario'
self.dbpass = 'contraseña'
self.dbname = 'nombre de la base de datos'
Schema:
El siguiente paso es definir el schema que estructura los datos con los que opera la API y las consultas que se pueden realizar, así como el formato de las respuestas. Este schema se incluye en un fichero denominado schema.graphql dentro del proyecto.
En este caso, vamos a contar con un recurso inventario y otro recurso producto. Para ambos se va a definir una consulta de listado completo y otra de búsqueda de un registro concreto por su identificador. Además, para el recurso producto vamos a definir tres mutaciones: crear, modificar y eliminar.
schema {
query: Query
mutation: Mutation
}
type Product {
id_product: ID!
name: String!
standard_cost: Float
list_price: Float
product_line: String
update_date: String
}
type Inventory {
id_product: ID!
amount: Int
}
type ProductResult {
success: Boolean!
errors: [String]
product: Product
}
type ProductListResult {
success: Boolean!
errors: [String]
product: [Product]
}
type InventoryResult {
success: Boolean!
errors: [String]
inventory: Inventory
}
type InventoryListResult {
success: Boolean!
errors: [String]
inventory: [Inventory]
}
type Query {
getProduct(id_product: ID!): ProductResult!
listProduct: ProductListResult!
getInventory(id_product: ID!): InventoryResult!
listInventory: InventoryListResult!
}
type Mutation {
createProduct(id_product: ID!, name: String!, standard_cost: Float!, list_price: Float!, product_line: String!, update_date: String): ProductResult!
updateProduct(id_product: ID!, name: String, standard_cost: Float, list_price: Float, product_line: String, update_date: String): ProductResult!
deleteProduct(id_product: ID): ProductResult!
}
Modelo de datos:
El siguiente apartado necesario es definir el modelo de datos para la conexión con la base de datos. Para ello se hace uso de la librería SQLAlchemy. Necesitaremos una clase por cada tabla a la que queramos acceder y los atributos de la clase deben coincidir con las columnas de dicha tabla (no teniendo que aparecer representadas todas las columnas que existen en la tabla si no queremos utilizarlas). Los nombres, tanto de la clase como de los atributos, tienen que coincidir con los de la tabla y las columnas respectivamente.
En nuestro caso contamos con una tabla d_product para los productos y otra tabla inventory para los datos de inventario asociados a cada producto. Para poder acceder a la conexión creada previamente en el fichero __init__.py se debe importar la variable correspondiente.
from api import db
class d_product(db.Model):
id_product = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String)
standardCost = db.Column(db.Numeric)
listPrice = db.Column(db.Numeric)
productLine = db.Column(db.String)
updateDate = db.Column(db.DateTime)
prod_line_complete = {"R ": "Road", "M ": "Mountain", "T ": "Touring", "S ": "Standard"}
def to_dict(self):
return {
"id_product": self.id_product,
"name": self.name,
"standard_cost": float(self.standardCost),
"list_price": float(self.listPrice),
"product_line": self.prod_line_complete.get(self.productLine),
"update_date": str(self.updateDate)
}
class inventory(db.Model):
id_product = db.Column(db.Integer, primary_key=True)
amount = db.Column(db.Integer)
def to_dict(self):
return {
"id_product": self.id_product,
"amount": self.amount
}
En este caso, el modelo está adaptado a nuestra base de datos y contiene algo de código específico para manejar los datos con que contamos. El modelo variará según la implementación y cómo se quieran adaptar los datos al extraerlos de la base de datos. Por ejemplo, en este caso, la columna productLine almacena la línea de producto con un solo carácter que resulta conveniente traducir a la palabra completa para hacerlo más comprensible de cara al usuario. Es por eso que se utiliza un diccionario (prod_line_complete) para traducir los caracteres a sus respectivos nombres. Esta traducción la hacemos en el paso que se explica en el siguiente párrafo.
Para que el modelo pueda retornar los datos según la consulta, debe contar con una función que genere un diccionario con pares clave-valor correspondientes con la definición del recurso en el schema. Es decir, si se observa nuestro método to_dict(), se está encargando de mapear los valores de las columnas a una estructura idéntica a la representada en el schemaque hemos definido previamente. Si el modelo no devuelve los datos en el mismo formato que el definido por el schema, la librería Ariadne no será capaz de tratar la información y las consultas no funcionarán.
Para hacer esto más visible, mostramos de nuevo el schema definido para el recurso producto:
type Product {
id_product: ID!
name: String!
standard_cost: Float
list_price: Float
product_line: String
update_date: String
}
Como se puede ver, se corresponde exactamente con el formato del diccionarioretornado:
return {
"id_product": self.id_product,
"name": self.name,
"standard_cost": float(self.standardCost),
"list_price": float(self.listPrice),
"product_line": self.prod_line_complete.get(self.productLine),
"update_date": str(self.updateDate)
}
Consultas y mutaciones:
Con el modelo creado, se puede proceder a implementar las consultas y mutaciones disponibles en la API. En este caso, por organización del código, las consultas se encuentran en un fichero queries.pyy las mutaciones en otro distinto, mutations.py.
Todas las consultas son muy similares, una estructura try-exceptque permite el tratamiento de las posibles excepciones que se puedan dar. Los parámetros obj e info deben reflejarse, pero en este caso no serán de utilidad. Como se puede observar, tras realizar la consulta de manera muy simple y obtener los datos, se construye un diccionario que representa la respuesta del servidor. Esta respuesta, se corresponde exactamente con la estructura de la respuesta reflejada en el schema:
type ProductResult {
success: Boolean!
errors: [String]
product: Product
}
Los campos marcados en el schema con ! tienen que ser devueltos obligatoriamente, como es el caso de success. Los demás, como es el caso de errors en la respuesta exitosa o producten la respuesta fallida, se pueden omitir.
from .models import d_product, inventory
from ariadne import convert_kwargs_to_snake_case
def listProduct_resolver(obj, info):
try:
products = [product.to_dict() for product in d_product.query.all()]
response = {
"success": True,
"product": products
}
except Exception as error:
response = {
"success": False,
"errors": [str(error)]
}
return response
@convert_kwargs_to_snake_case
def getProduct_resolver(obj, info, id_product):
try:
product = d_product.query.get(id_product)
print(product)
response = {
"success": True,
"product": product.to_dict()
}
except AttributeError:
response = {
"success": False,
"errors": ["Product matching {id} not found"]
}
return response
def listInventory_resolver(obj, info):
try:
inventory_list = [element.to_dict() for element in inventory.query.all()]
response = {
"success": True,
"inventory": inventory_list
}
except Exception as error:
response = {
"success": False,
"errors": [str(error)]
}
return response
@convert_kwargs_to_snake_case
def getInventory_resolver(obj, info, id_product):
try:
inv_result = inventory.query.get(id_product)
print(inv_result.to_dict())
response = {
"success": True,
"inventory": inv_result.to_dict()
}
except AttributeError:
response = {
"success": False,
"errors": ["Product matching {id} not found"]
}
return response
Se puede observar que en las funciones getProduct_resolver y getInventory_resolver, se recibe un parámetro adicional correspondiente con el id del producto por el que filtrar. Esto también debe estar reflejado en el schema:
type Query {
getProduct(id_product: ID!): ProductResult!
listProduct: ProductListResult!
getInventory(id_product: ID!): InventoryResult!
listInventory: InventoryListResult!
}
El caso de las mutaciones es muy similar. Para facilitar la asociación entre el schema y las correspondientes funciones y poder visualizar los parámetros, se muestra de nuevo el apartado que define las mutaciones:
type Mutation {
createProduct(id_product: ID!, name: String!, standard_cost: Float!, list_price: Float!, product_line: String!, update_date: String): ProductResult!
updateProduct(id_product: ID!, name: String, standard_cost: Float, list_price: Float, product_line: String, update_date: String): ProductResult!
deleteProduct(id_product: ID): ProductResult!
}
Y el código correspondiente:
from ariadne import convert_kwargs_to_snake_case
from api import db
from api.models import d_product
from datetime import datetime
@convert_kwargs_to_snake_case
def create_product_resolver(obj, info, id_product, name, standard_cost, list_price, product_line):
try:
date_time = datetime.now()
product = d_product(id_product=id_product, name=name, standardCost=standard_cost, listPrice=list_price, productLine=product_line, updateDate=date_time)
db.session.add(product)
db.session.commit()
response={
"success": True,
"product": product.to_dict()
}
except ValueError:
response = {
"success": False,
"errors": ["Incorrect date and time format. Should be yyyy-mm-dd hh:mm:ss"]
}
return response
Para aclarar un poco la lógica de la actualización de un registro de producto, en primer lugar se está extrayendo el producto de la base de datos y, posteriormente, en caso de que los parámetros no sean nulos, se asignan a los atributos correspondientes de la clase producto para después actualizar la base de datos.
@convert_kwargs_to_snake_case
def update_product_resolver(obj, info, id_product, name, standard_cost, list_price, product_line):
try:
product = d_product.query.get(id_product)
if product:
if name:
product.name = name
if standard_cost:
product.standardCost = standard_cost
if list_price:
product.listPrice = list_price
if product_line:
product.productLine = product_line
product.updateDate = datetime.now()
db.session.add(product)
db.session.commit()
response = {
"success": True,
"product": product.to_dict()
}
except AttributeError:
response = {
"success": False,
"errors": ["Product matching id {id_product} not found"]
}
except ValueError:
response = {
"success": False,
"errors": ["Incorrect date and time format. Should be yyyy-mm-dd hh:mm:ss"]
}
return response
@convert_kwargs_to_snake_case
def delete_product_resolver(obj, info, id_product):
try:
product = d_product.query.get(id_product)
db.session.delete(product)
db.session.commit()
response = {
"success": True,
"product": product.to_dict()
}
except AttributeError:
response = {
"success": False,
"errors": "Product not found"
}
return response
Aplicación web:
Por último, se crea un fichero app.py que contendrá las asociaciones entre funciones de Python y las consultas definidas en el schema. Además, contendrá los métodos asociados al endpoint /graphql, endpoint único de la API. En otras palabras, las APIs de GraphQL no requieren rutas específicas para cada recurso (/productos, /inventario), sino que se pueden hacer todas las consultas desde el mismo punto de entrada.
En primer lugar, importamos todo lo necesario. Entre los imports, se encuentra el PLAYGROUND_HTML que podemos utilizar como interfaz web gráfica para realizar consultas a la API y testearla.
from api import app, db
from ariadne import load_schema_from_path, make_executable_schema, graphql_sync, snake_case_fallback_resolvers, ObjectType
from ariadne.constants import PLAYGROUND_HTML
from flask import request, jsonify
from api.queries import listProduct_resolver, getProduct_resolver, listInventory_resolver, getInventory_resolver
from api.mutations import create_product_resolver, update_product_resolver, delete_product_resolver
A continuación se carga el schema y se asocia a las funciones implementadas para las consultas y mutaciones.
query = ObjectType("Query")
mutation = ObjectType("Mutation")
query.set_field("listProduct", listProduct_resolver)
query.set_field("getProduct", getProduct_resolver)
query.set_field("listInventory", listInventory_resolver)
query.set_field("getInventory", getInventory_resolver)
mutation.set_field("createProduct", create_product_resolver)
mutation.set_field("updateProduct", update_product_resolver)
mutation.set_field("deleteProduct", delete_product_resolver)
type_defs = load_schema_from_path("schema.graphql")
schema = make_executable_schema(type_defs, query, mutation, snake_case_fallback_resolvers)
Finalmente se define la funcionalidad asociada a cada ruta de la aplicación web.
@app.route("/")
def init():
return "Running..."
@app.route("/graphql", methods=['GET'])
def graphql_playground():
return PLAYGROUND_HTML, 200
@app.route("/graphql", methods=["POST"])
def graphql_server():
data = request.get_json()
success, result = graphql_sync(
schema,
data,
context_value=request,
debug=app.debug
)
if success:
status_code = 200
else:
status_code = 400
return jsonify(result), status_code
Para lanzar la aplicación, en una terminal deben ejecutarse los siguientes mandatos:
La primera vez:
export FLASK_APP=app.py (Linux) | set FLASK_APP=app.py (Windows)
Para lanzar la aplicación:flask run
Como se mencionaba al inicio, todo este proyecto, a excepción de la base de datos, está disponible en un repositorio de GitHub:
https://github.com/Stratebi/api_graphql
6. Conclusiones
Para concluir el contenido desarrollado, se ha podido comprobar que GraphQL es un enfoque muy potente y que consigue exitosamente añadir mucha libertad a la hora de realizar consultas a una API.
El paradigma Rest que predomina actualmente en el mundo web permite consultas prediseñadas en las que el servidor retorna al cliente un recurso con unos campos fijos que posteriormente el cliente tendrá que filtrar en muchos casos. GraphQL simplifica este trabajo al permitir consultas flexibles y adaptadas a cada situación, otorgando al cliente de una API, en cierto modo, la misma capacidad que si pudiera ejecutar por sí mismo la consulta SQL (SELECT … FROM … WHERE) que necesita.
Este planteamiento puede ahorrar trabajo de desarrollo al permitir que una misma API proporcione servicio a necesidades muy distintas, sin tener que prefabricar todas las consultas posibles o demandadas, como sería necesario en una API Rest.