


Las bases teóricas con las reglas basicas sobre que cosa es una ETL las puso Ralph Kimball en su libro “ Data Warehouse Lifecycle Toolkit (Segunda Edición) ”
En el se explica que las ETL se pueden agrupar en 34 sub-sistemas y a su vez en 4 ámbito:
-
Data Extraction
- 1. Data Profiling
- 2. Change Data Capture (CDC)
- 3. Extraction
-
Cleansing and Conforming Tasks
- 4. Data Cleansing Subsystem
- 5. Error Event Management
- 6. Auditing
- 7. Removing Duplicates
- 8. Data Conformance
-
Data Delivery
- 9. Slowly Changing Dimensions (SCD)
- 10. Surrogate Key Generator
- 11. Hierarchy Manager
- 12. Special Dimensions Manager
- 13. Fact Table Builders
- 14. Surrogate Key Management
- 15. Bridge Table Builder
- 16. Late Arriving Data Handler
- 17. Dimension Manager
- 18.Fact Table Provider
- 19. Aggregate Generation
- 20. OLAP Cube Builder
- 21. Data Propagation Manager
-
Management
- 22. Scheduler
- 23. Backup System
- 24. Recovery and Restart
- 25. Version Control
- 26. Version Migration
- 27. Work flow Monitor
- 28. Sorting
- 29. Data Lineage and Dependency
- 30. Problem Escalation
- 31. Paralleling and Pipelining
- 32. Security
- 33. Compliance Manager
- 34. Metadata Repository
Uno de los primeros problemas a los que normalmente nos enfrentamos en Stratebi a la hora de realizar un proceso ETL es el CDC (Cange Data Capture) , es decir, cómo cargar los datos, no en carga total sinó los datos “nuevos”.
Para ello se nos presentan diferentes opciones que me han parecido interesantes cuanto menos por la categorización:
-
Source Data-Based CDC
o Un mundo ideal:En el sistema origen tenemos algo que nos proporciona esta información como puede ser:
- Los registros tienen una serie de timestamps que indican la fecha de creación y la última fecha de actualización (Todavía no he visto ningún sistema tan bien hecho)
- Se puede hacer uso de las secuencias exixtentes en los sistemas origen
- Trigger-Based CDC o Una buena idea pero poco realista: Cada vez que se realiza un insert, update o delete en el sistema origen se dispara un trigger que registra el cambio en nuestra Stagging Area
- Snapshot-Based CDC o A lo bruto: Se guarda una foto en nuestra stagging area y cuando volvemos a cargar realizamos una comparación entre ambas.
- Log-Based CDC : Se procesa el log de la base de datos en busca de inserts, deletes y updates. Eso se puede hacer facilmente con bases de datos como Oracle y PostgreSQL lo que no todo el mundo sabe es que también se puede hacer con MySql.
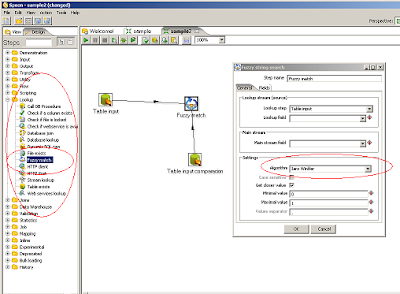
Otro de las cosas interesantes es ( el look-up ) paso “ Fuzzy Match ” que nos permite aplicar diferentes algoritmos de lógica difusa para buscar duplicados.
{kind=link}
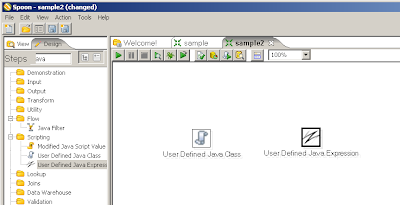
Siguiendo con los pasos interesantes existen el User Defined Java Expression que viene a ser como el javascript pero mucho mas rápido y el User Defined Java Class Que nos permite definir una clase java y hacer lo que nos venga en gana.
Finalmente, de momento comentar un par de cosas referentes al rendimiento.
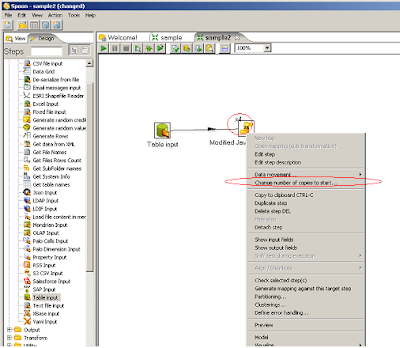
Sabíais que se pueden instanciar mas de una réplica de cada paso? Por ejemplo, el paso javascript que todos sabemos que es lento, se le puede decir que inicie 4 u 8 copias para mejorar el renimiento.
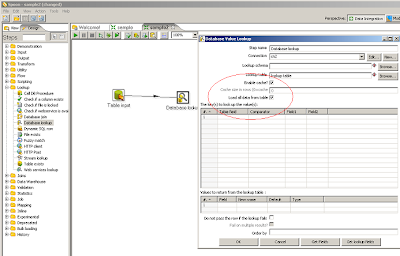
Sabías que se puede habilitar la caché de los databases lookup? Sabías que se le puede decir que mapee toda la tabla a memoria para mejorar el rendimiento? Habilitar la caché nos permite que una búsqueda ya hecha no se vuelva a repetir y tenerlo todo en memoria nos permite que se lea la tabla entera al arrancar el proceso y todas las búsquedas, para cada registro se realicen en memoria en vez de hacer N búsquedas en la tabla.
…. Seguiremos informando.